
导读:随着云原生概念的兴起,越来越多的系统服务在往云原生演进,在演进阶段如何保障系统的稳定性和高可用性,是每个系统负责人都要关注的问题,通过混沌工程可以很好的解决这个问题。ChaosBlade 是阿里巴巴开源的一款混沌工程实验执行工具,其易用性和丰富的场景受到大家的广泛关注。本文整理自阿里巴巴技术专家肖长军(穹谷)在 QCon 全球软件开发大会(上海站)2019 上的演讲,他围绕云原生架构介绍了 ChaosBlade 的设计、特性与实践,以及如何基于 ChaosBlade 搭建一个自动化的混沌实验平台。

大家好,欢迎大家来听混沌专场,我是来自阿里巴巴的肖长军,花名穹谷,之前对外分享过什么是混沌工程以及如何实施混沌工程。云原生和混沌工程在今年都是比较火的概念,混沌工程在阿里巴巴实施也近十年的时间,我今天主要围绕 ChaosBlade 分享,ChaosBlade 是阿里巴巴在 2019 年 4 月份开源的一款混沌工程的实验工具,我今天的讲的内容包含这三点:一是 ChaosBlade 是什么,ChaosBlade 的定位及它的特性有哪些,然后再重点会介绍 ChaosBlade 的详细设计;接下来会介绍 ChaosBlade 在云原生架构下具体的设计,以及使用案例;最后再分享一下基于 ChaosBlade 搭建的,在阿里云上输出的混沌实验平台 AHAS Chaos,一个简单易用的故障演练平台。接下来我们先来看一下混沌工程在阿里巴巴内部的演进。

在 12 年阿里内部就上线了 EOS 项目,用于梳理分布式服务强弱依赖问题,同年进行了同城容灾的断网演练。15 年实现异地多活,16 年内部推出故障演练平台 MonkeyKing,开始在线上环境实施混沌实验,然后是 18 年,这一年输出了两个产品,一个是阿里云内部专有云,就专门对专有云,阿里的一些产品做高可用测试的 ACP,还有对外将阿里云,在阿里的高可用架构经验输出的一个 AHAS 应用高可用服务产品,该产品包含架构感知,能自动感知你的架构拓扑,系统拓扑;还有限流降级功能,就是应用防护这一块;另外一个就是故障演练,也就是 AHAS-Chaos 平台,后面也会重点介绍。2019 年 4 月份刚才也提到开源了 ChaosBlade,然后下半年我们开始做专有云的混沌实验平台的一个输出。我们为什么要做开源呢?因为当时已经开源的工具存在以下问题。

例如场景能力分散,大家熟知的 Chaos Monkey,混沌猴子,只杀 EC2 实例;Kube Monkey 只杀 K8s pod。除了能力分散之外,还有上手难度大,因为不同的工具它的使用方式也不一样。还有缺少实验模型,难以实践,并且场景难以沉淀。这些问题就会导致很难实现平台化,你很难通过一个平台去囊括这些工具。我们当时提出了一套混沌实验模型,很好的解决了这些问题,ChaosBlade 也是基于混沌实验模型来研发的,而且混沌工程在阿里已实践多年,所以我们将沉淀的场景开源出来,服务于混沌工程社区。

ChaosBlade 是一款遵循混沌实验模型的混沌实验执行工具,具有场景丰富度高,简单易用等特点,而且扩展场景也特别方便,开源不久就被加入到 CNCF Landspace 中,成为主流的一款混沌工具。ChaosBlade 这些特点得益于以下这个混沌实验模型。
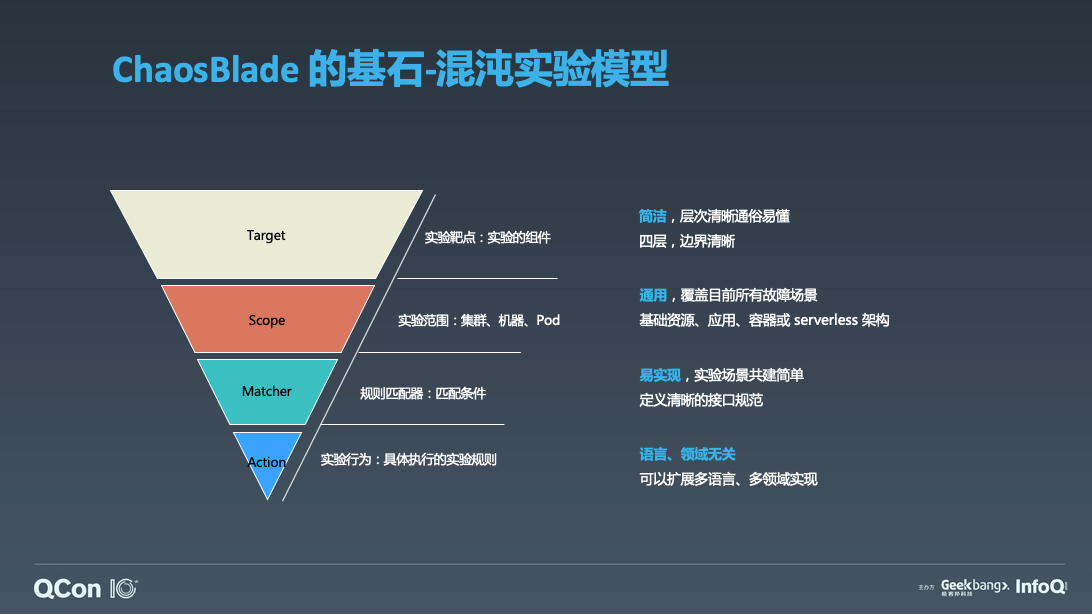
此模型很简洁,这个倒三角模型供分为四层:第一个是 Target,我们演练的目标是什么;然后是 Scope,定义了我们实验范围;其次是 Matcher,我们实验场景触发匹配的规则有哪些;最后一个是 Action,我们执行的实验行为,也就是我们要做什么演练。举个例子,比如我们要对一台机器上的 dubbo 应用调用 serviceA 服务做调用延迟实验。那么我们来对齐一下实验模型,首先 Target 就是 dubbo,我们要对 dubbo 服务做演练。Scope 是本机,就是这一台机器上 dubbo 应用。然后匹配规则是服务名 serviceA,那么它的 action 是什么?是延迟,通过实验模型描述之后,层次清晰,而且该模型覆盖目前所有的实验场景。我们再来看一下基于混沌实验模型 ChaosBlade 目前所具备的场景。
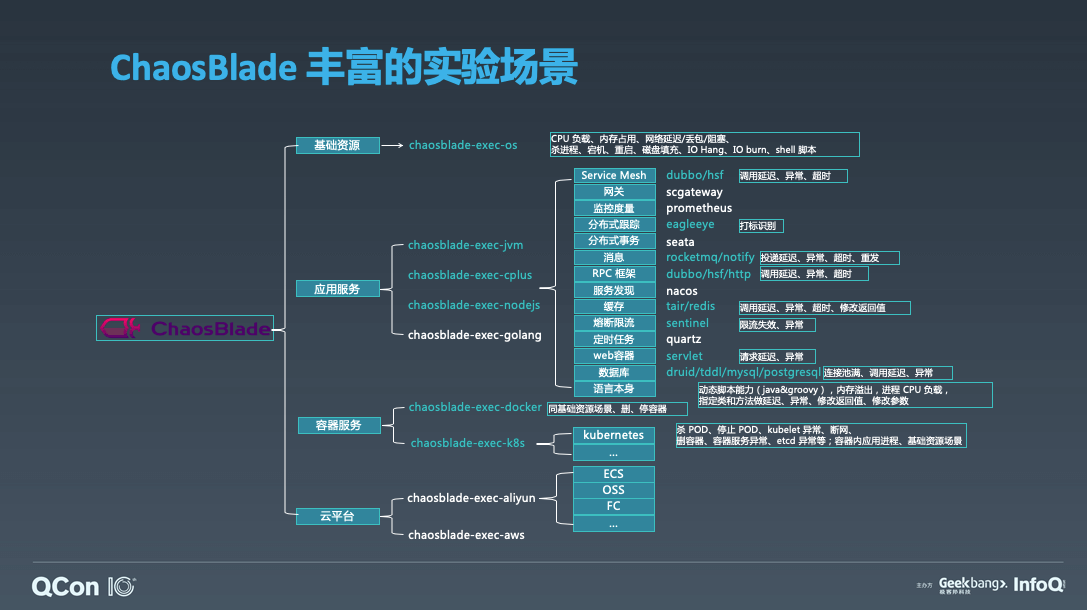
我把 ChaosBlade 的场景分为四大类,前面这一列绿色字体是项目工程,后面的绿色字体代表已经实现的组件,后面的绿框框起来的白字的,就是它所支持的实验场景举例。第一大类场景是基础资源,包含的实验场景如 CPU 满载、内存占用,网络延迟,进程 Hang 等。另外一类是应用服务,应用服务的场景取决于你应用的构建语言,我们目前支持的是 JAVA、C++ 和 NodeJS,每一个应用服务下面又细分了这些组件,后面列举的这些绿色字体的是我们已经支持的组件。再一类场景涉及到容器服务,容器服务的话,我们目前支持 Docker 和 K8s。我们支持的 K8s 场景例如杀 Pod,Kubelet 异常,删容器等。最后的一类是云平台,待实现中。这个是 ChaosBlade 故障场景大图。在这丰富的场景下,ChaosBlade 的易用性也非常强。

重点介绍一下,ChaosBlade 是个直接下载解压就可以使用的工具,不需要安装,然后它支持的调用方式包含 CLI 方式,直接执行 blade 命令,比如这里举的做网络延迟的例子,你添加 -h 参数就可以看到非常完善的命令提示,比如我要一个 9520 端口调用做网络丢包,对齐前面的实验模型,我们就可以看到,它的演练目标是 network,它的 action 是丢包,它的 matcher 就是调用远程的一个服务端口 9520。执行成功后会返回实验结果,每一个实验场景我们都会作为一个对象,它会返回一个实验对象的 UID,此 UID 用于后续的实验管理,比如销毁、查询实验都是通过此 UID 来做的。要销毁实验,也就是恢复实验,直接执行 blade destroy 命令就可以了。ChaosBlade 另一种调用方式是 Web 方式,通过执行 server 命令对外暴露 HTTP 服务,那么在上层,你如果自己构建混沌实验平台的话,你直接可以通过 HTTP 请求去调用就可以了。所以说 ChaosBlade 具有很好的易用性,那么它是如何设计的呢?
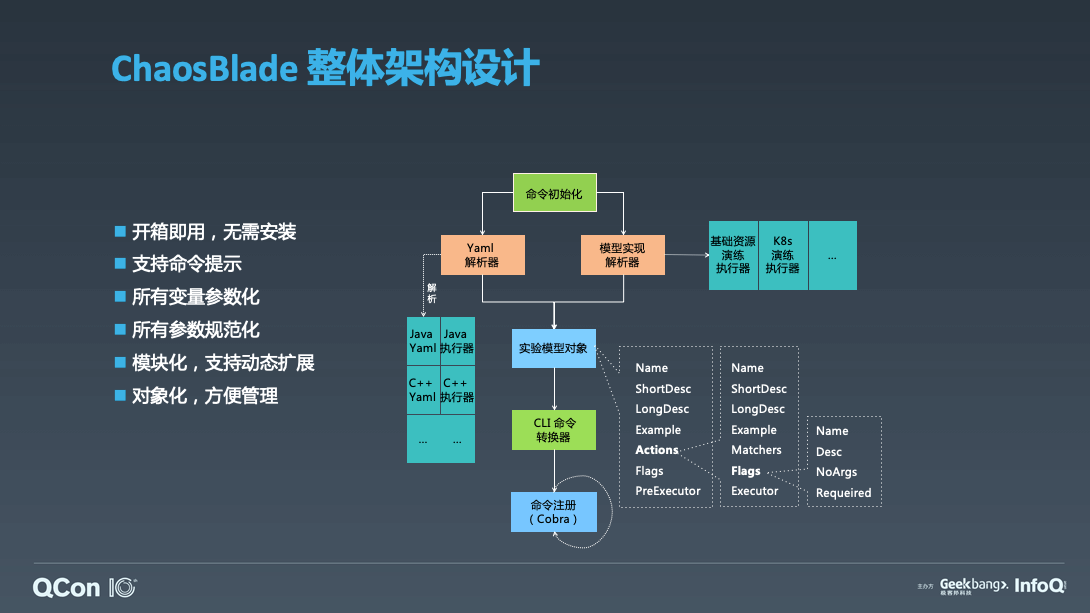
我将 ChaosBlade 的设计总结为这六点。使用 Golang 构建,实现跨平台,并且解压即用;工具使用采用 CLI 的方式,使用简单,具备完善的命令提示;遵循混沌实验模型定义场景接口,所有场景基于此接口实现,将模型转换为 cobra 框架所支持的命令参数,实现变量参数化、参数规范化,并且通过实验模型 Yaml 描述,可以很方便的实现多语言、多领域的场景扩展。而且将整个实验对象化,每个实验对象都会有个 UID,方便管理。这个是 ChaosBlade 的一个整体设计。那么我们再通过一个例子来看一下 ChaosBlade 如何使用。
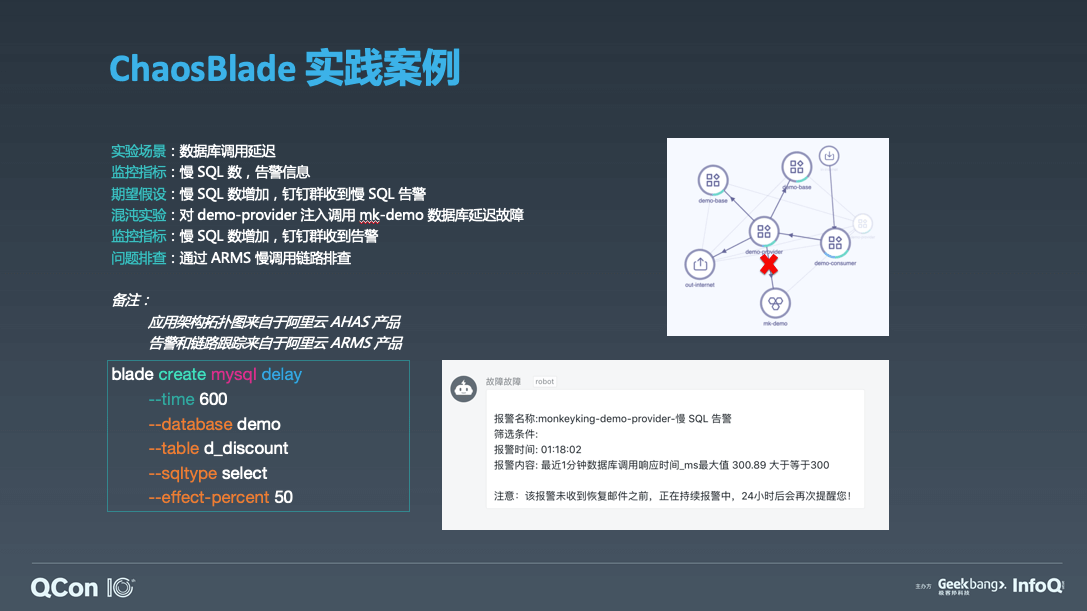
这个例子的是主要验证服务调用数据库延迟。在讲这个例子之前,先看一下右上角 demo 的应用拓扑图,这个拓扑图来自于 AHAS 架构感知,从这个拓扑图中我们可以看出 consumer 服务调用 provider,provider 调用 mk-demo RDS 数据库,同时也调用下游的 base 服务,这个是三层的微服务调用。这里我们 provider 服务有两个实例,所做的实验就是 provider 调用数据库 mk-demo 发生延迟。在执行混沌实验之前,就要有明确的监控指标,因为执行混沌实验的步骤包含要执行的实验计划是什么,我们执行的预期是什么,然后执行实验,我们执行实验如果不符合预期,我们的下一步的推进计划是什么,后面再做持续的验证,所以说我们这里定义了一个监控指标,我们监控慢 SQL 数以及监控报警。那么我们的期望假设就是慢 SQL 数增加,钉钉群收到相关的报警信息。我们执行的实验是对其中一个 provider 服务实例注入调用 mk-demo 数据库延迟的故障,大家可以看到左下角,这个就是对 demo 数据库注入延迟的命令,可以看出命令非常简洁清晰,比如很明确的表达出我们的实验目标是 mysql,我们的实验场景是做延迟,后面这些都是这些数据库的匹配器,比如表,查询类型,还有控制实验的影响条数等等。ChaosBlade 可以很有效的控制实验的爆炸半径,可以控制到影响的条数,控制影响百分比,而且还有各种匹配器来匹配,控制粒度很细。那么我执行完这条命令,就开始对这台机器的 provider 服务注入故障,大家可以看到我注入故障之后,这里这个图就是我立刻收到了钉钉的报警,那么这个 case 是符合预期的 case,但是即使符合预期的 case,也是有价值的,需要相关的开发和运维人员是要去排查延迟的问题根因并恢复。这里的监控告警使用的是阿里云的 ARMS 产品,除了监控告警功能,还可以抓取到详细的链路调用堆栈,这里很清晰的展示出哪条 SQL 语句执行慢。这个是整个的一个 ChaosBlade 使用案例,它可以验证系统的告警是否有效,开发和运维的响应速度是否达到要求,那么除了刚才提到的告警和开发和人员响应速度之外,混沌实验的价值我总结为三部分。

第一部分就是人员,人员的话这里列举了四个角色,比如对于架构师来说,那么架构师他要做系统设计,比如设计高容错的系统或者是面向失败的系统,那么可以通过混沌工程去验证系统的韧性和容错容灾的能力。对于开发和运维来说,通过混沌工程,可以提高故障的应急效率,或完善排查问题的工具。对于测试来说的话,之前的测试涉及到从功能测试、性能测试,这些都是从用户的角度去来测试系统的。那么通过混沌工程可以从系统的角度来验证系统中潜在的问题,可以提早暴露线上的问题,然后降低故障的复发率。对于产品和设计来说,他们可以通过混沌工程来演练页面上的一些事件,比如商品详情页,哪项出现问题,用户体验度如何。所以说混沌工程是适用于每一个人的。另一部分是系统,系统的话,前面也提到了可以通过混沌工程提升系统的容错、容灾能力。还有就是基础能力和运维高可用,就是通过混沌工程去验证你的基础服务,比如你的监控体系,你的告警体系,是不是高可用的,如果这些不是高可用的,那么当故障出现的时候,你有可能不能及时发现系统的故障,不能及时收到故障报警,排查问题也有可能遇到阻碍,所以说你要保证你的基础设施是高可用的,它可以通过混沌工程去验证你这些基础服务。最后一个是流程,就通过混沌工程,你可以验证整个故障发生的处理流程,比如阿里的话,故障都有明确的等级划分,通过混沌工程可以推进故障等级的划分,验证你的联系人的有效性,比如经过多年有可能这些人都离职了,但是他还在告警联系人里,该在的而不在,这都是问题。这是在流程方面,除了故障应急还有一个故障管理,故障管理的话主要是做故障沉淀,后面的话故障统计以及故障复盘,以及故障场景沉淀,持续做演练,防止故障再次发生。这里是对混沌工程价值的一个总结,除了这些,在云原生时代,混沌工程的价值是什么?

我们在讲价值之前先看一下目前云原生架构所包含的技术及相关的稳定性挑战。以下列举了云原生相关的技术。
云设施指公有云、专有云和混合云等,是云原生系统的基础设施,基础实施的故障可能对整个上层业务系统造成很大影响,所以说云设施的稳定性是非常重要的。容器服务的挑战可以分两大类,一类是面向 k8s 服务提供商,服务是否稳定,另一类是面向用户,配置的扩缩容规则是否有效,实现的 CRD 是否正确,容器编排是否合理等问题。微服务,分布式服务的复杂性,单个服务的故障很难判断对整个系统的影响;service mesh,sidecar 的服务路由、负载均衡等功能的有效性,还有 sidecar 容器本身的可用性。serverless,现在基本上都是函数加事件的形式,资源调度是否有效,而且 serverless 服务提供商屏蔽了一些中间件,你能掌控的是函数这些服务,那么你可以通过混沌工程去验证你函数调用的一些配置,比如超时配置,还有相关的一些降级策略,这些是否合理。以上这些云原生架构稳定性相关的挑战,再来看云原生本身的的特点,谈到云原生,可以说云原生是一个理念,包含我这里列举的云原生相关的技术,但是他们都有相同的共性,比如弹性可扩展、松耦合、容错性高、还有一些易于管理,便于观察这些特性。所以说在云原生时代,混沌工程对云原生系统的价值我总结为。

云原生时代下,通过混沌工程能推进系统”云原生“化.这句话的意思就是能让你的系统通过混沌工程能达到云原生的极致,就是刚才提到的那些特点,具有非常高的容错能力,具有非常高的弹性。这是我对混沌工程在云原生架构下价值的总结。
我们再来看一下 ChaosBlade 在云原生架构下场景的实现方案。
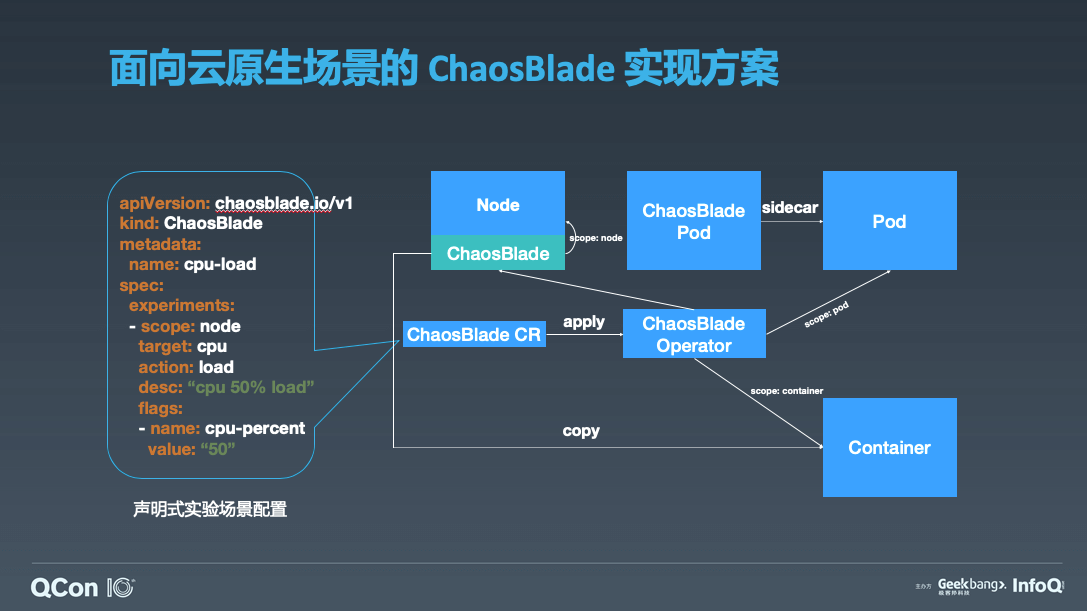
ChaosBlade 通过 Operator 创建了自定义控制,通过 Helm 等方式可一键安装,用来管理实验资源对象,大家可以看到左边这些声明式的实验场景配置,它也是严格遵循前面的混沌实验模型,配置非常的方便。这里举个例子,比如我对集群中的节点做负载实验,负载 50%,那么我就可以定义好这个资源,通过 kubectl 去执行。也可以使用 chaosblade 自身的 blade 命令去执行。ChaosBlade Operator 除了定义控制器之外,会以 daemonset 的方式在每个节点上部署一个 chaosblade-tool pod 来执行混沌实验。不同的实验场景内部实现方式不同,比如 Node 实验场景,其上面部署的 chaosblade-tool 内部执行即可,而 Container 内的实验场景,控制器会将 chaosblade 包拷贝到目标 Container 中执行。技术实现核心的话就是将混沌实验定义为 K8s 资源,传递给 operater 来识别并执行资源。这个是 ChaosBlade 的一个整体的实验方案。ChaosBlade 非常友好的支持 K8s 实验场景,目前包含 Node、Pod、Container 资源场景。我们来看具体的一个案例。
这个例子是随机删除业务 Pod,然后验证业务的稳定性,右边是对实验场景 yaml 描述,这里的 case 是随机筛选实例进行删除,每一个服务只杀一台实例,通过 system=demo 标签随机的筛选这些服务实例,然后指定删除的每个服务 Pod 实例数量。可以看到我这边的监控指标是业务指标,就是下方的页面截图,另一个是 Pod 数。这里的期望假设是业务不受影响,Pod 的副本数在预期之内。这是一个实验假设。我们来看实验的结果。我执行完实验之后,我通过查询 Pod 来验证,然后大家可以看到每一类服务,它会被删掉一个 Pod 实例,然后会被 K8s 重新拉起。但是删不是我们的目的,混沌工程有一点非常重要,就是我们做故障演练的目的不是触发故障,我们目的是通过故障来验证系统的架构的缺陷,发现问题并迭代修复这些缺陷,来提高系统的韧性。所以说我们这边要去验证这个结果。这边是拿 K8s 官方的一个 guestbook 这个 demo 去做的演示,那么我执行完这个实验之后,大家可以看下方截图,整个实验的前后的页面展示是不一样的,之前提交的数据不存在了。那么这个 demo 就存在数据持久化高可用的问题。我后面分析了一下,它为什么会造成这个问题,因为如果删除掉 master 之后,它没有做数据持久化存储,你前面提交的这些数据就会丢失。它会把数据同步到 slave 节点,由于没有数据,它会覆盖掉原有保存的这些数据。所以说大家通过这个 case 可以看到,随机杀 Pod 去可以验证你整个的业务的稳定性和容错能力,这个 case 是不符合我们预期的,所以说我们后面要去推动业务,去修复,去完善这个问题。前面是对 ChaosBlade 的整体介绍,包括什么是 ChaosBlade,ChaosBlade 的易用性,ChaosBlade 支持哪些场景,ChaosBlade 的架构设计,还有拿具体的案例去讲混沌工程的价值,然后包括 ChaosBlade 在面向云原生的系统,我们该如何去做。接下来我们讲一下混沌实验平台。为什么要做平台?因为前面也提到了混沌实验执行步骤,你执行混沌工程,很重要的一点是要做持续化验证,如果只是工具的话,那么你很难去做自动化的持续验证,所以说你需要使用平台。这里重点介绍一下阿里云 AHAS 这个云产品下面的 AHAS Chaos 故障演练平台。会先介绍平台的设计理念,然后拿一个案例去讲该如何去使用。

我们先来看一下 AHAS Chaos 平台设计理念。AHAS Chaos 具有开放性,它可以集成和被集成,它可以通过小程序来拓展,可以集成别的服务,比如你可以调用第三方监控,或者你自身的服务来做一些事前的准备,或者是做一些结果验证,这是它的集成能力。它的被集成就是它提供一些 OpenAPI,你可以基于这些 OpenAPI 去查询、创建、执行混沌实验,而且你可以基于它去做一些自己业务相关的一些处理。这个是被集成。操作简洁,它把整个的前面提到的混沌实验执行的步骤,它分成了四个阶段。第一个阶段就是准备阶段,比如我可以做一些事情的准备,还有执行阶段,就是执行实验。检查阶段就是做验证,还有恢复阶段。所以说操作是非常简洁。而且前面提到的那些实验场景,会有很多参数,那么你要通过 ChaosBlade 的话,你要查这个命令帮助才能看到这些实验参数是什么,平台的话它会自动解析出这个参数来展示,并有详细的说明,你只需要下拉框选择或自己填就可以了,它的操作非常简洁。编排灵活,它具有拖拽的一些编排能力。还有专家经验,就是我们把一些我们内部的,或者是云上的一些高考用的经验,会通过引演练模板的形式给提供给大家,大家可以套用这个模板来进行相关的实验。这个是 AHAS Chaos 平台设计理念。我们再来看一下 AHAS Chaos 平台的架构设计。
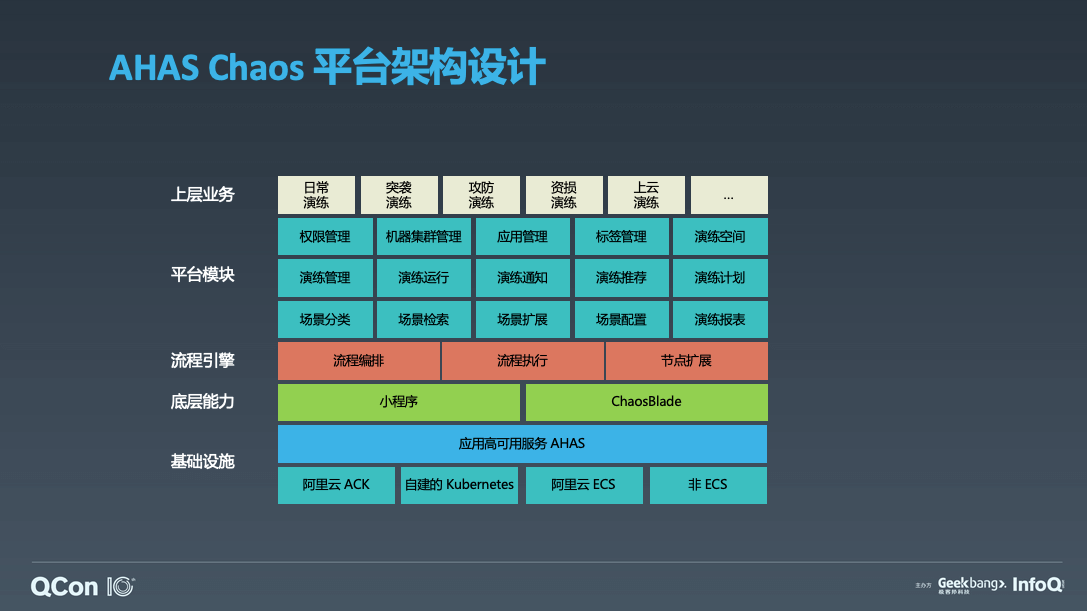
这个是 AHAS Chaos 平台架构图,你可以部署在阿里云的 ACK 或自建的 K8s 集群,以及 ECS 或非 ECS。基于 AHAS 底座运行,前面也提到了,AHAS Chaos 有小程序的能力,你可以自定义扩展,它底层集成了 ChaosBlade,具有 ChaosBlade 这些丰富的场景。在往上平台模块,前面也提到了它的演练管理,演练运行,还有演练空间、演练计划、演练报表等,这些平台都是提供功能。然后它的开放式的能力,它开放 openAPI,你可以基于这个平台去构建自己的平台,比如这里提到的阿里巴巴目前的演练,第一个日常演练,就是你可以做一些服务的日常演练,那么你也可以做突袭,所谓突袭的话就是在不通知业务方的情况下,去对他们的系统注入故障,来验证他们故障的告警、故障的响应速度、故障的恢复能力,这是突袭演练。攻防演练的话就是大家商量好,一起来做一个攻防对抗。这是攻防演练。还有资损演练、上云演练等。这是 AHAS Chaos 平台的架构设计。下面我们通过一个 case 来分享平台的使用。

面向于原生架构的一个 AHAS Chaos 平台使用的例子,右下角的话是宠物商店的 Demo,右上方是这个 Demo 的架构拓扑图,是基于 AHAS 产品架构感知的能力,此产品一键安装,安装完之后,不需要做任何事情,它就会自动感知出整个系统应用的架构拓扑图,还有非常详细的进程、网络、机器、容器等信息。所以说这边的话,我通过 AHAS 架构感知去做一个数据库延迟实验,验证 Pod 的水平扩容能力。Demo 运行在阿里云 ACK 上,对 provider Pod 数据库做网络延迟实验,然后去验证预期。发生了网络延迟,一个具备容错能力的系统,它会水平扩展新的 Pod。因为数据库延迟之后,RT 会升高,RT 升高之后就会影响用户,那么一个容错的一个韧性比较好的系统,它会水平扩展 Pod,来降低这个延迟的负载,把原有 Pod 隔离或者是删除掉。所以监控指标就是 RT 和 Pod 数,我期望的假设是 RT 会短暂的升高,但是很快会恢复。左下角是 AHAS Chaos 平台页面,大家可以看到,通过平台可以把这些参数暴露出来,你只需要去做简单的配置就可以了,无需去写 Yaml 文件。平台还提供了演练编排和演练计划,你只需要保存这个实验,点击立即运行,就可以方便的去执行实验,你可以结合架构感知验证 Pod 容器的变化。这是对 AHAS Chaos 故障演练平台的介绍。

右上方的图片是 ChaosBlade 的开源讨论群和应用高可用服务(AHAS)的交流群,这两个都是钉钉群。ChaosBlade 的一些技术文档也都会在群里分享,关于 AHAS 的问题可以在群里咨询。
以上是我对今天分享的总结。基于实验模型实现的 ChaosBlade 不仅场景丰富,而且使用简单,很友好的支持云原生场景。如果企业想去试用或者是落地混沌工程的话,AHAS Chaos 是个不错的选择。
以上就是我这次的分享,谢谢大家。