
ChaosBlade
随着云原生的发展,云原生应用一致性、可靠性、灵活编排的能力让大部分企业选择将应用往云上迁移,但同时云基础设施在稳定性、高可用、可观测方面也接受着强大的考验。 ChaosBlade 是阿里巴巴开源的一款遵循混沌工程原理和混沌实验模型的实验注入工具,帮助企业提升分布式系统的容错能力,并且在企业上云或往云原生系统迁移过程中提供业务连续性保障。 ChaosBlade Operator 是 Kubernetes 平台实验场景的实现,将混沌实验通过 Kubernetes 标准的 CRD 方式定义,很方便地使用 Kubernetes 资源操作的方式来创建、更新、删除实验场景,包括使用 kubectl、client-go 等方式执行,同时也可以使用 chaosblade cli 工具执行。
本文将主要介绍 ChaosBlade 在 Kubernetes 中故障注入的底层实现原理、版本优化过程以及大规模应用演练测试。
资源模型
在 Kubernetes 中部署应用,通常我们会选择将应用定义为 pod、Deployment、Statefulset 等资源类型,这些都是 Kubernetes 已经内置的;在实际应用中,面对复杂的应用场景,内置的资源类型是无法满足我们需求的,Operator 是一种解决复杂应用容器化的一种方案,通过自定义资源和自定义控制器来实现复杂应用容器化,chaosblade-operator 正是就是基于 Operator 实现的。
在 Kubernetes 中安装完 chaosblade-operator 后,会生成一个 deployment 资源类型的 chaosblade-operator 实例、一个 daemonset 资源类型的 chaosblade-tool 实例、一个自定义资源定义,当然还包含 RABC、SA 等等其他资源;
 chaosblade 将自定义资源类型定义为 chaosblade ,简称 blade ;每次新建演练就可以通过 kubectl 或者 chaosblade cli 创建 blade 实例资源,blade 资源本身也包含了 chaosblade 混沌实验定义;
chaosblade-operator 会监听 blade 资源的生命周期,当发现有 blade 资源实例被创建时,同时就能拿到混沌实验定义,然后解析实验定义,去调用 chaosblade-tool 真正地注入故障;
chaosblade-tool 是 daemonset 资源类型,一个 Node 节点必定会部署一个 pod,从 Linux Namespace 的维度出发,该 pod 网络、PID 命名空间与 Node 节点处在同一命名空间,因此可以做到部分 Node 级别的演练。
chaosblade 将自定义资源类型定义为 chaosblade ,简称 blade ;每次新建演练就可以通过 kubectl 或者 chaosblade cli 创建 blade 实例资源,blade 资源本身也包含了 chaosblade 混沌实验定义;
chaosblade-operator 会监听 blade 资源的生命周期,当发现有 blade 资源实例被创建时,同时就能拿到混沌实验定义,然后解析实验定义,去调用 chaosblade-tool 真正地注入故障;
chaosblade-tool 是 daemonset 资源类型,一个 Node 节点必定会部署一个 pod,从 Linux Namespace 的维度出发,该 pod 网络、PID 命名空间与 Node 节点处在同一命名空间,因此可以做到部分 Node 级别的演练。
生命周期
在资源模型中,简单提到了 chaosblade-operator 会监听 blade 资源的创建; chaosblade-operator 实则会监听整个 blade 资源的生命周期,blade 资源的生命周期等同演练实验生命周期;chaosblade-operator 会根据 blade 资源状态去更新实验的状态。
| blade 资源状态 | 实验过程 | CPU 负载案例 |
|---|---|---|
| apply(新建) | 新建演练 | 新建 CPU 负载演练 |
| running(运行中) | 演练运行中 | CPU 负载中 |
| deleted(被删除) | 恢复演练 | 恢复演练 |
故障注入
在资源模型中提到了 chaosblade-operator 发现有 blade 资源实例被创建时,同时就能拿到混沌实验定义,然后解析实验定义,去真正地注入故障;那么 chaosblade-operator 是如何去真正地注入故障呢?
其实在早期的 chaosblade-operator 版本中,大部分场景是通过将 chaosblade cli 工具通过 kubenetes API 通道复制到容器内部,然后再去容器内部执行命令来实现故障注入,整体实现方案入下图;
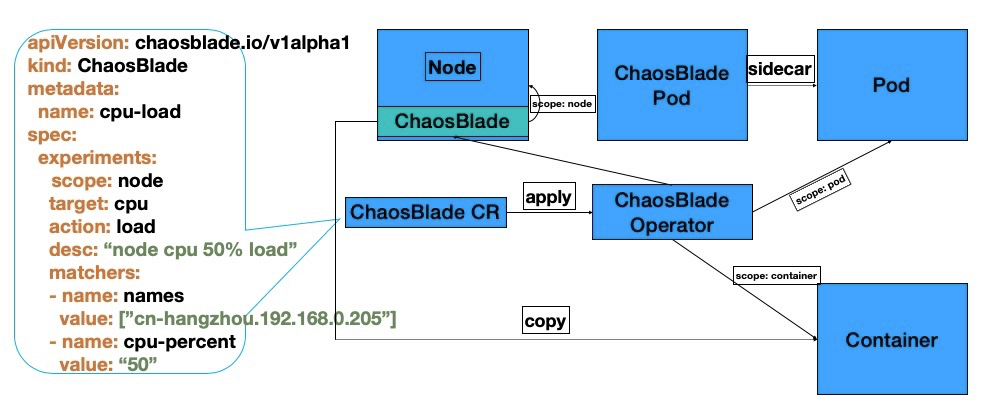 可以看到左边的 yaml 定义就是 Chaosblade 混沌实验模型定义,也是 blade 资源实例的一部分信息,当 blade 资源通过 kubectl apply 以后,chaosblade-operator 会监听到资源的创建,同时解析到实验定义;
当解析到 scope = node 的时候,会找到 node 节点所在 chaosblade-tool pod 中执行命令,这些动作几乎对整个集群来说资源消耗也是极少的;
但是当解析到 scope = pod 或者 scope = container 的时候,大部分场景 chaosblade-operator 会把 chaosblade cli 工具本身复制到业务容器内部,然后再去业务容器执行命令,工具包的大小、实验选择的容器数量、决定了资源的消耗大小,往往兼容性、版本更新等等都得不到很好的保障;
在新版本的 chaosblade-operator 版本中,将在下面最初的问题、优化过程、实现原理等小节详细介绍。
可以看到左边的 yaml 定义就是 Chaosblade 混沌实验模型定义,也是 blade 资源实例的一部分信息,当 blade 资源通过 kubectl apply 以后,chaosblade-operator 会监听到资源的创建,同时解析到实验定义;
当解析到 scope = node 的时候,会找到 node 节点所在 chaosblade-tool pod 中执行命令,这些动作几乎对整个集群来说资源消耗也是极少的;
但是当解析到 scope = pod 或者 scope = container 的时候,大部分场景 chaosblade-operator 会把 chaosblade cli 工具本身复制到业务容器内部,然后再去业务容器执行命令,工具包的大小、实验选择的容器数量、决定了资源的消耗大小,往往兼容性、版本更新等等都得不到很好的保障;
在新版本的 chaosblade-operator 版本中,将在下面最初的问题、优化过程、实现原理等小节详细介绍。
最初的痛点
当一个云原生应用达到一定规模时,去进行演练;
- 集群环境:1000 个 node 节点
- 目标应用:deployment 有 5000 个副本数
- 演练场景:对该应用对外提供的接口返回延迟 1000 毫秒
注入慢
首先需要找到 5000 个副本,将工具复制到容器,在进入容器执行命令,假设一个复制工具耗费 100 毫秒,那么整个过程耗费时间 500000 毫秒,这对用户来说简直是不可接受的。
网络带宽占用
将工具复制到容器,至少需要调用 kubernetes api 5000次,假设一个可执文件大小 5MB , 5000 次需要占用总带宽流量 5000x5=25000MB ,对 IO 影响简直就是灾难级别的;
兼容性问题
假设我们已经通过层层考验,已经工具将工具复制进去,当工具本身依赖了依赖一些命令,比如网络(tc)、磁盘(dd)等容器中又没有这些命令,或者版本不兼容该如何处理?
只读 pod
对于配置了只读文件系统的 pod,文件是不可写入的,因此压根就没发将工具复制进去
侵入型
将工具留在业务容器内部,等同于将工具生命周期与容器绑定在一起;
优化过程
在最初版本的迭代过程我们做过很多优化,同步转异步、包瘦身、按需复制等等优化方案,虽然一定程度上提高了注入的效率,但是没有解决问题的本质,还是受限于主机的 IO 性能; 无论是同步转异步、包瘦身、按需复制等优化方案,本质没法解决工具复制带来的一些问题;羊毛出在羊身上,解决问题就得解决问题的本质,从 Linux 虚拟化技术的角度思考,如何不复制工具就在能容器中注入故障呢?
Linux 虚拟化
对于 Linux 虚拟化技术而言,核心实现原理就是 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力,以及基于 rootfs 的文件系统; Linux Namespace 可以让进程(容器)处在一个独立的沙箱环境,Linux Cgroups 可以限制该沙箱内进程的资源使用,比如限制 CPU、内存的使用率等等;
Linux Cgroups
Linux Cgroups 可以限制沙箱内进程的资源使用,并且也可以人为将某个进程的资源使用交给已经存在的某个的 Linux Cgroups 控制,而通常容器的资源使用率统计也是 Linux Cgroups 控制组下面进程的使用情况计算出来的;此时在宿主机启动的一个 CPU 负载的进程,并且将该进程交给某个已经存在的容器的控制组控制,就相当于给该容器注入了 CPU 负载场景。
在 docker 上面尝试在不侵入该容器的情况下,给容器 nginx 注入 CPU 负载的场景。首先启动一个 nginx 容器 docker run -it -d -p 8087:80 --cpus 0 --name nginx nginx,容器启动后 docker 会给该容器新建一个 Cgroups 控制组,在该命令中会限制该容器只能使用一个核心的 CPU 。
- 找到容器的进程 PID,该进程是容器启动时第一个进程
docker inspect --format "{{.State.Pid}}" nginx
- 查看进程的 Cgroups 控制组,可以看到有 CPU、内存、blkio 等等很多 Cgroup 子系统
cat /proc/$(docker inspect --format "{{.State.Pid}}" nginx)/cgroup
11:devices:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
10:blkio:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
9:pids:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
8:memory:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
7:freezer:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
6:perf_event:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
5:cpuset:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
4:hugetlb:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
3:cpuacct,cpu:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
2:net_prio,net_cls:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
1:name=systemd:/docker/4bcf3de8de2904b3308d8fc8dbdf6155cad7763fa108a32e538402156b6eacaa
- 查看 CPU 控制组进程列表,可以有很多进程受该容器 Cgroup CPU 子系统控制;按照这个思路,我们只需要启动一个 CPU 负载进程,并且将进程 PID 写入这个文件,就可以做到容器 CPU 注入;
cat /sys/fs/cgroup/cpu$(cat /proc/$(docker inspect --format "{{.State.Pid}}" nginx)/cgroup | head -n 1 | awk -F ':' '{print $3}')/tas
ks
7921
7980
7981
7982
7983
- CPU 负载脚本
#! /bin/bash
while [ 1 ]
do
echo "" > /dev/null
done
- 执行 CPU 负载脚本后找到 PID ,将进程写入容器进程列表文件
echo PID >> /sys/fs/cgroup/cpu$(cat /proc/$(docker inspect --format "{{.State.Pid}}" nginx)/cgroup | head -n 1 | awk -F ':' '{print $3}')/tas
ks
- 此时可以观察到容器 CPU 达到 100%,而宿主机未达到,说明 CPU 负载只对容器产生了效果,运用同样的方式,可以做到资源占用型的任何故障场景,比如内存、IO 等
最终成功在不侵入该容器的情况下,给该容器注入 CPU 负载的场景。通过 Cgroups 控制组,还能做到其他 Cgroups 支持的子系统的场景注入,比如 CPU 高负载、内存占用高、IO 高负载等等;
Linux Namespace
通过 Linux Cgroups 做到了不侵入该容器的情况下,给该容器注入 CPU 负载的场景,同时也能支持 CPU 高负载、内存占用高、IO 高负载等等; 对于其他类型的故障,比如网络延时、文件删除等等,则需要通过另外一种方式来实现 , 就是 Linux Namespace 的隔离能力。
Linux Namespace 提供了网络、IPC、MNT 等命名空间隔离的能力,在容器独立的 Namespace 下,新建一个文件,新启动一个进程等等操作也是其他容器不可感知和观测到的;
在 docker 上面尝试在不侵入该容器的情况下,给 nginx 容器注入网络延时的场景。首先启动一个 nginx 容器 docker run -it -d -p 8087:80 --cpus 0 --name nginx nginx,在宿主机开放端口 8080 代理到容器内 80 端口, 容器启动后会有独立的网络命名空间,监听 80 端口。
宿主机网络延时
TC (TrafficControl) 用于Linux内核的流量控制,可以做到网络延时、丢包等等,先尝试利用 TC 在宿主机上注入网络延时,比如需要注入一个网络延时 100ms 的场景,在宿主机上执行如下命令
#延时
tc qdisc add dev eth0 root netem delay 100ms
此时在客户端打开浏览器访问 http://IP:8087 会查看到有稳定 100ms 的延时,而仔细观测后会发现其他端口也会有延时,比如 22、3306 等等;(注意,只能在别的客户端机器访问,不能在直接在当前机器通过 curl http://127.0.0.1:8087 验证)
# 恢复
tc qdisc del dev eth0 root
容器内网络延时
如何在容器中注入一个网络延时呢?其实非常简单,Linux 提供了 setns() 函数,可以方便进入指定进程所在命名空间;如果注入网络延时,只需要进入目标容器的网络命名空间即可;
- 找到容器的进程
docker inspect --format "{{.State.Pid}}" nginx
- 进入容器所在命名空间,nsenter 命令最终会调用 setns() 函数,如果没有此命令,需要安装 util-linux 包
nsenter -t 7921 -n
- 此时查看 IP 相关信息,返回的则是容器内 IP 相关信息
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
124: eth0@if125: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:13 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.19/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
- 注入网络延时也只会对容器生效
tc qdisc add dev eth0 root netem delay 100ms
此时在客户端打开浏览器访问 http://IP:8087 会查看到有稳定 100ms 的延时,但是并不会对其他端口生效,比如 22、3306 等等;因为实际延时本身是作用在容器网络命名空间内,并且不会对宿主机生效。
最终成功在不侵入该容器的情况下,给该容器注入网络延时的故障场景。Linux 提供了很多维度的命名空间隔离,并且允许加入任何类型的命名空间,通过 Linux Namespace ,还能做到文件删除、杀进程等等场景
chaosblade 实现
在 Chaosblade 1.6.x 版本已经通过 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力实现容器化故障注入,chaosblade-operator 主要负责监听 crd 资源状态变更,chaosblade-operator 不再去执行故障注入的操作,而是由作为 dasemonset 类型资源的 chaosblade-tool 主要负责真正地注入故障,整体实现方案入下图:
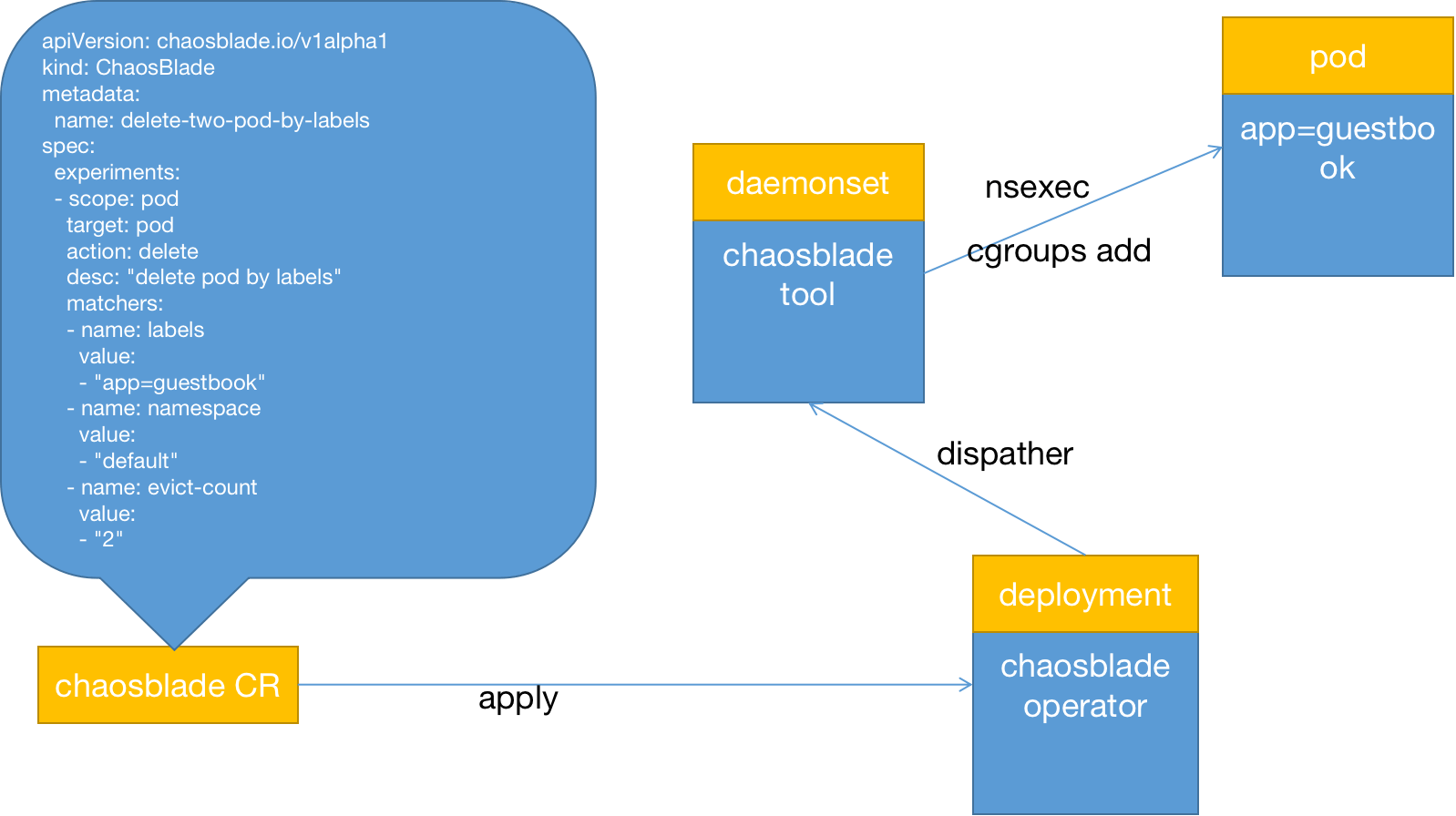
同理可以看到左边的 yaml 定义就是 Chaosblade 混沌实验模型定义,也是 blade 资源实例的一部分信息,当 blade 资源通过 kubectl apply 以后,chaosblade-operator 会监听到资源的创建,同时解析到实验定义;
当解析到 scope = node 的时候,会找到 node 节点所在 chaosblade-tool pod 中执行命令,这些动作几乎对整个集群来说资源消耗也是极少的,这部分和早期版本几乎是没有任何区别的;
但是当解析到 scope = pod 或者 scope = container 的时候, chaosblade-operator 并不会把 chaosblade cli 工具本身复制到业务容器内部,更不会去容器里面执行相关命令,极大地减少了对 kubernetes API 的依赖;那么 chaosblade-operator 究竟是怎么做的呢? chaosblade-operator 仅仅通过 kubernetes API 找到实验对象,即目标业务 pod,然后继续找到目标业务 pod 所在的节点上部署的 chaosblade-tool pod ,解析 pod 里面的容器名称,最后封装命令直接在 chaosblade-tool 执行命令,去真正地执行故障注入;在 chaosblade-tool 层注入故障的时候已经没有 pod 的概念,这一层是 chaosblade-operator 去解析和封装的;
为何在目标业务 pod 所在的节点上部署的 chaosblade-tool 执行命令,能够直接对目标业务 pod 生效呢?如果你仔细阅读了之前 Linux 虚拟化 章节,相信你已经有了答案;chaosblade-tool 作为 daemonset 资源,拥有宿主机 PID 命令空间切换的能力,同时在资源定义时也已经将宿主机 /sys/fs 目录挂载进 chaosblade-tool pod,使得 chaosblade-tool 能够自由更改进程的 cgroups 控制组;所以 chaosblade-tool 可以对该宿主机上任意容器注入故障,将 chaosblade-operator 的一部分工作剥离了出来,使用 chaosblade-operator 的职责更简单且轻量级,符合最初的设计理论;
Chaosblade-tool 通过 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力实现容器化故障注入,不论是性能、兼容性、稳定性都有极大的提升;因为大部分场景是可以直接 chaosblade-tool 执行的,只要保证 chaosblade-tool 容器依赖库版本和命令能够支持演练,就不会存在兼容性、稳定性等问题;就好比在早起的版本中,我们甚至需要考虑目标业务容器中没有 dd、tc 命令怎么办,或者 dd 版本命令不兼容又怎么办等等问题。
无论 kubernetes 使用 docker、contained、crio 或者其他容器运行时相关技术,Chaosblade 都能做到快速兼容,因为 Chaosblade 通过 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力实现容器化故障注入,对容器运行时相关的 API 依赖并不大,只需要找到容器 1 号进程即可;
场景分析
首先先从 chaosblade 支持的故障场景出发,基于进程维度故障注入的方式可以分为两类:资源占用和状态变更; 资源占用 注入的方式很容易理解,通过运行可持续占用资源的进程,并且保证进程的持续运行,来达到占用系统资源的目的,通常有 CPU 满载、内存满载、磁盘IO负载、端口占用 等; 状态变更 注入的方式可能不是那么贴切,此“状态”可以理解为磁盘可用大小、文件权限、pod 状态等等,实现这种类型的故障注入,我们需要通过运行一个进程来打包修该目标资源的状态即可,当然【状态变更】的方式也有可能进程需要运行很长时间来完成,与【资源占用】不同的是,它需要一个终态来完成故障的注入,即进程执行成功,而不是需要保证进程的持续运行。 将 chaosblade 支持的故障场景分类,得到如下表格:
| 场景 | 分类 | 是否加入 Cgroup 控制 | 需要进入的命名空间 |
|---|---|---|---|
| CPU | 资源占用 | 是 | PID |
| 内存 | 资源占用 | 是 | PID |
| 磁盘IO | 资源占用 | 是 | PID |
| 磁盘容量 | 状态变更 | 否 | MNT |
| 杀进程 | 状态变更 | 否 | PID |
| 网络延时、丢包、乱序(主要 tc 实现的场景) | 状态变更 | 否 | NET |
| 网络端口占用 | 资源占用 | 否 | NET |
| 文件场景 | 状态变更 | 否 | MNT |
在资源占用的故障注入模式下,需要判断资源是否是宿主机级别共享的,并且是 Linux Cgroups 已经支持的子系统,比如 CPU、内存、磁盘IO 等等,只需要进入目标容器进程的 PID 命令空间,然后加入目标容器进程控制组即实现故障注入;也有比较特别的,比如网络端口占用,虽然它被列为属于资源占用的故障注入模式,但是端口是独立命名空间内共享的资源,所以他是需要通过 NET 命名空间切换才能实现的。
在状态变更的故障注入模式下,通过需要根据具体场景,进入目标容器进程的命名空间去做一些操作,比如网络场景,需要进入 NET Namespace;文件场景需要进入 MNT Namespace 等等。
在 chaosblade-1.6.x 版本下,也已经提供命名空间切换的实现,比如进入容器(进程 PID 是 35941)命名空间执行 ls 命令:
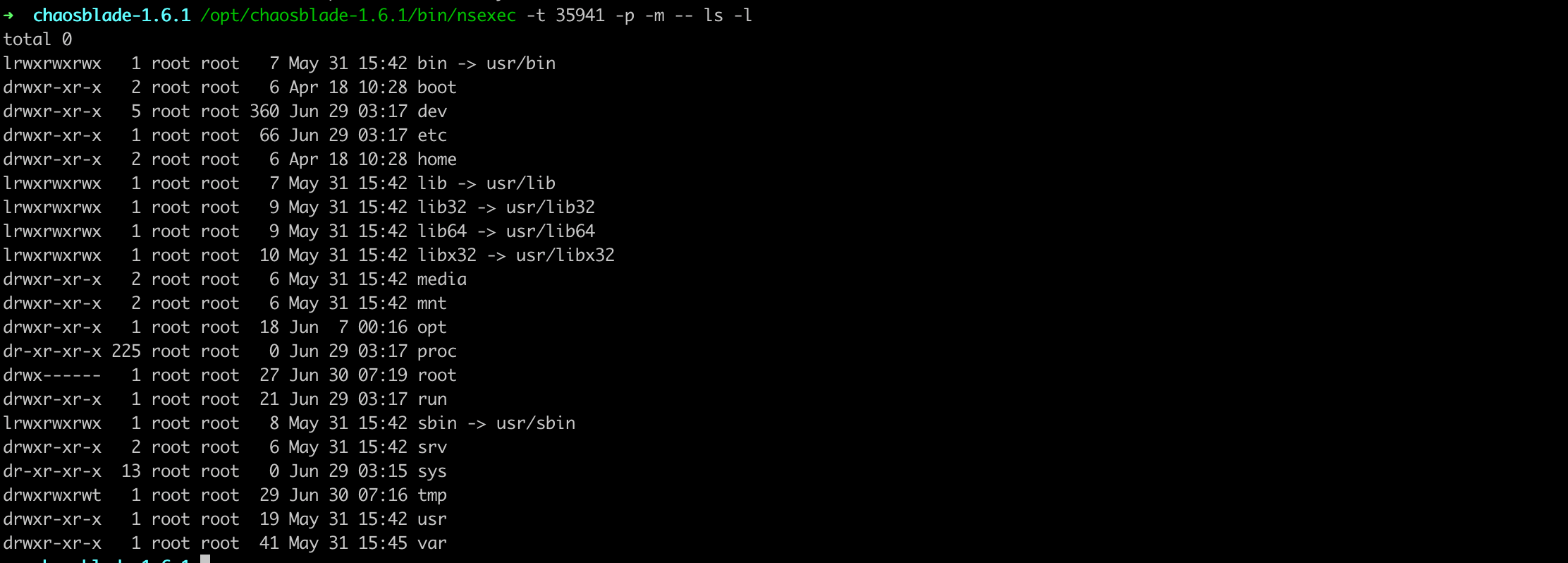 结合场景的注入模式以及 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力,大多数情况下都能分析出场景应该通过什么样的方式在容器注入故障;
结合场景的注入模式以及 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力,大多数情况下都能分析出场景应该通过什么样的方式在容器注入故障;
大规模应用演练
在 Chaosblade 1.6.x 版本已经通过 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力实现容器化故障注入,相比通过工具复制的方式,效率提升显著、兼容性更强、而且无侵入。 在此章节通过实际场景来观测 chaosblade-operator 早期版本和 Chaosblade chaosblade-operator 1.6.x 版本的注入性能和资源消耗情况。
实验案例
分别在 kubernetes 部署 chaosblade-operator 1.5.0 版本和 chaosblade-operator 1.6.1版本,分三次实验,注入 CPU load 场景来观察注入性能、磁盘IO、网络带宽;
- 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 20
- 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 50
- 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 100
实验环境
三节点 kubernetes 集群,master 为可调度模式
| 节点/资源 | CPU | 内存 |
|---|---|---|
| master1 | 4c | 16g |
| node1 | 4c | 16g |
| node2 | 4c | 16g |
实验结果
chaosblade-operator 1.5.0 版本
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 20;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
注入耗时
注入耗时达到 57s
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 5m
{"code":200,"success":true,"result":"4fce727793e239cb"}
real 0m57.851s
user 0m0.811s
sys 0m0.208s
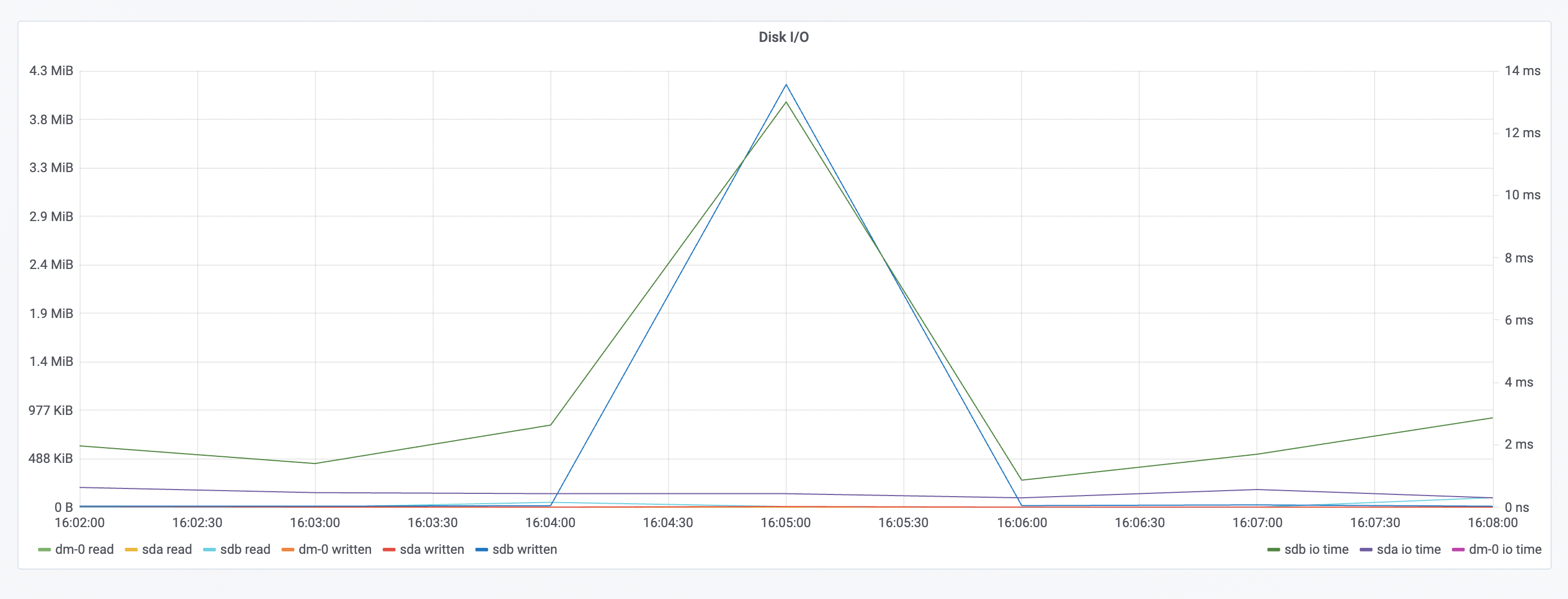
资源消耗
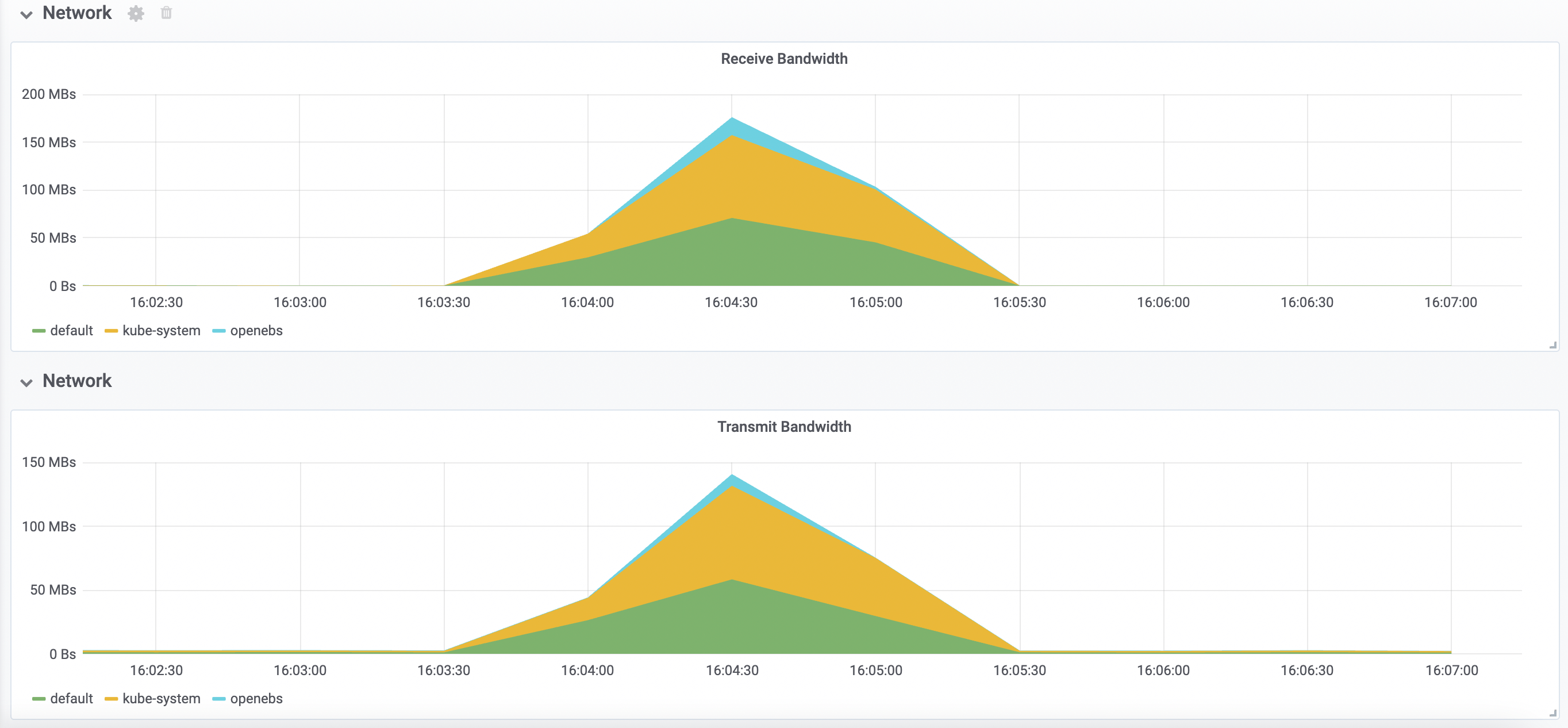
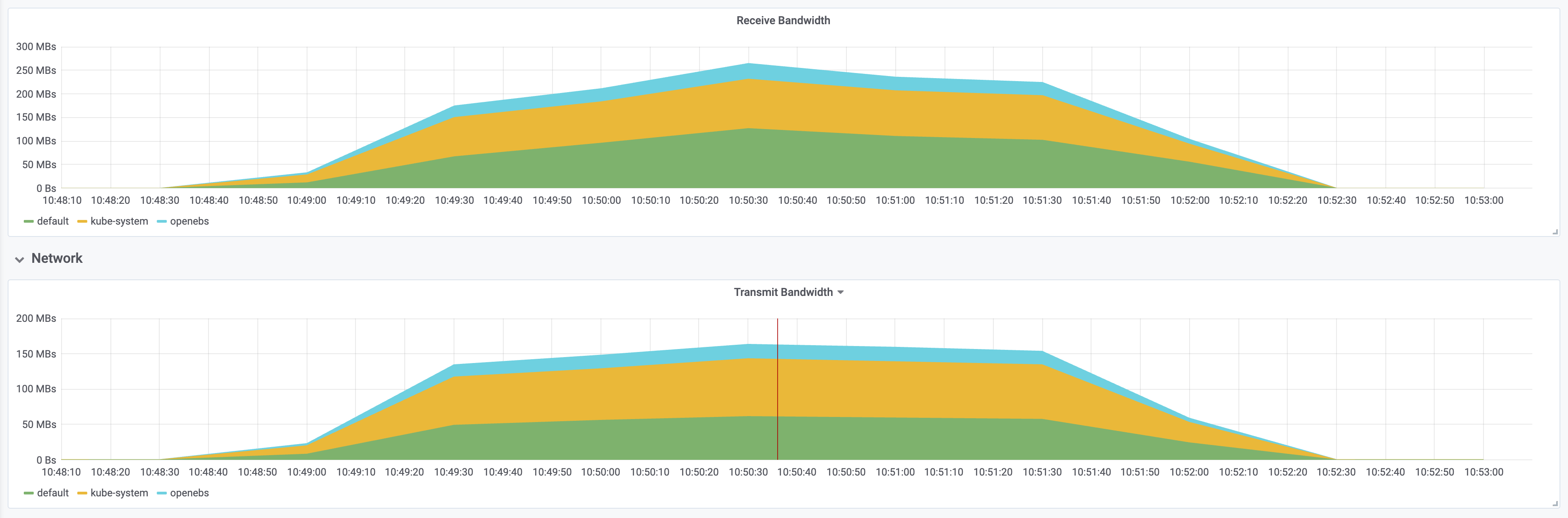
可以看到网络带宽接受峰值达到 180MBs 左右,传输峰值达到 140MBs 左右
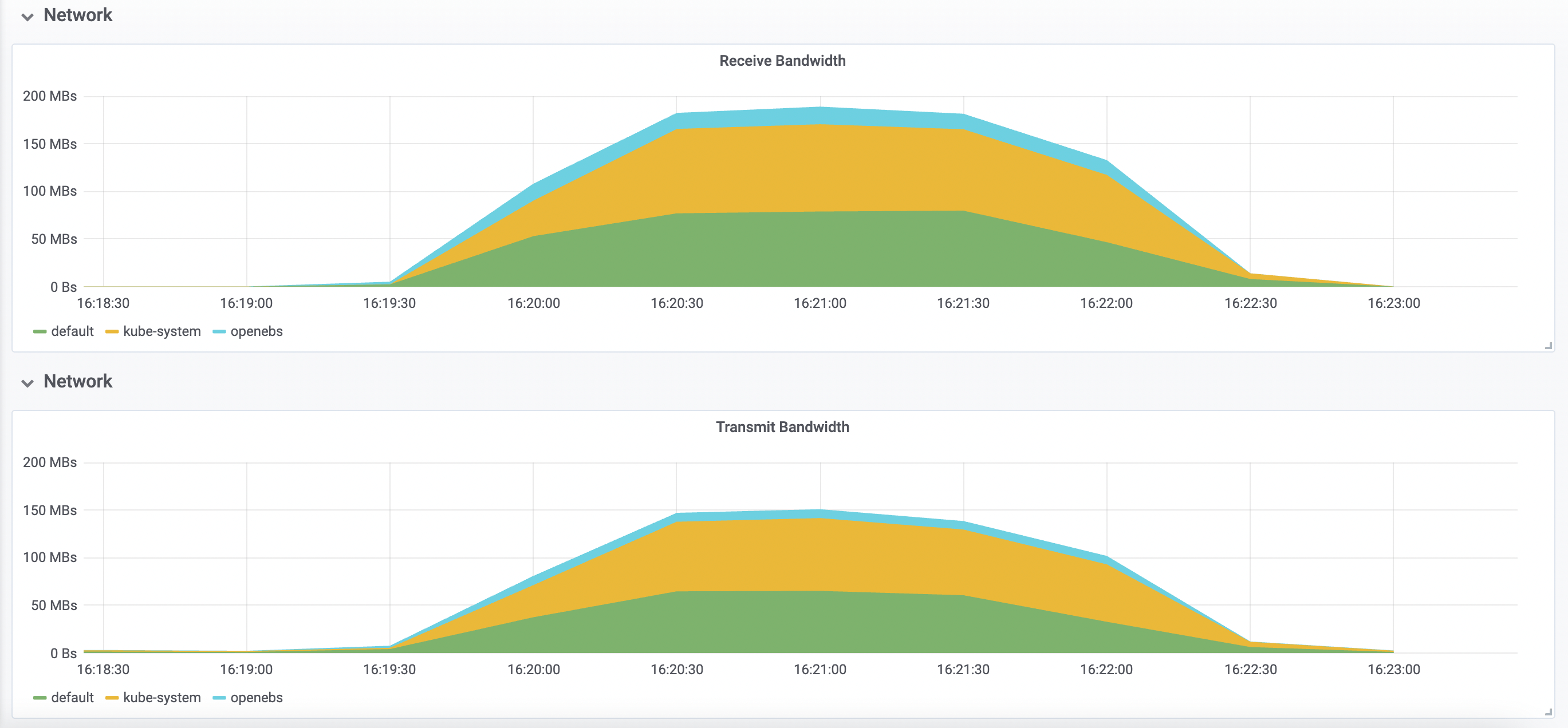
 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 50;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 50;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
注入耗时
注入耗时达到 2m25.806s
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 5m
{"code":200,"success":true,"result":"71e07348af26e4aa"}
real 2m25.806s
user 0m1.010s
sys 0m0.239s
资源消耗
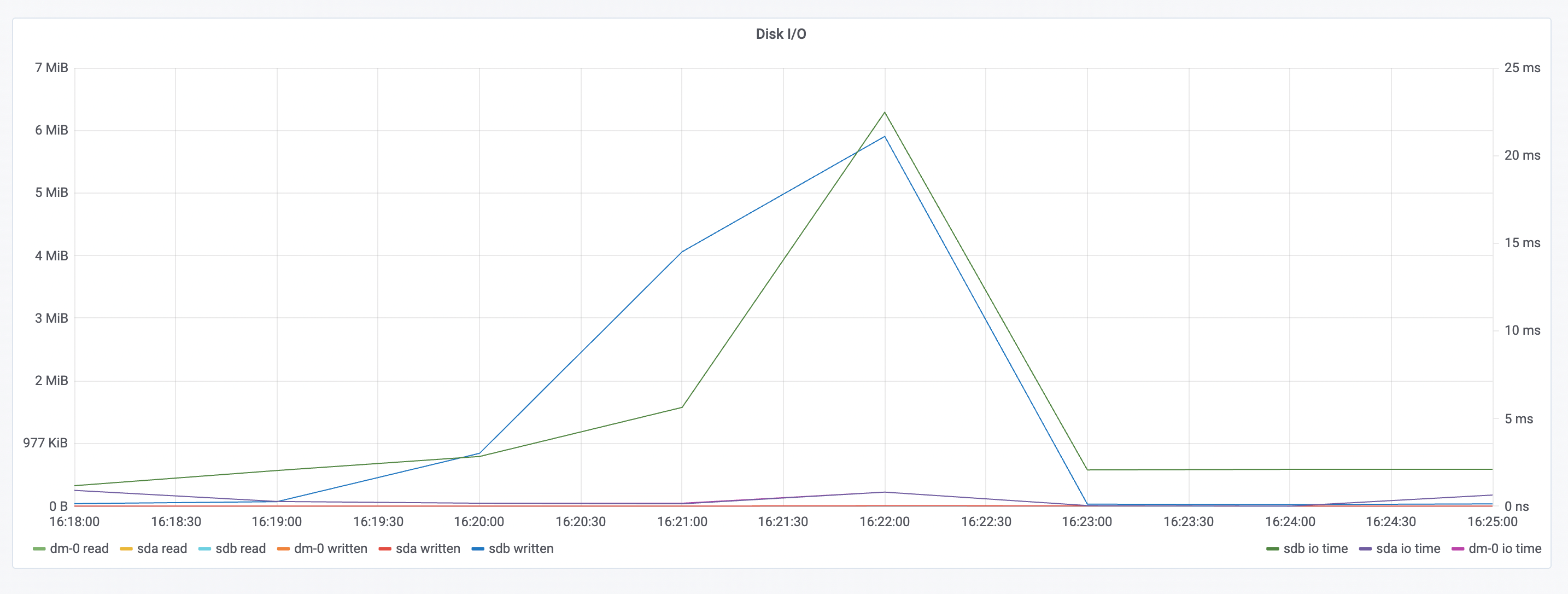
 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 100;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,为了避免出现超时情况,不太好评估注入耗时,所有此时将等待时间设置为 20 分钟;
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 100;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,为了避免出现超时情况,不太好评估注入耗时,所有此时将等待时间设置为 20 分钟;
注入耗时
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 20m
{"code":200,"success":true,"result":"cc477f2c632e2510"}
real 4m59.776s
user 0m1.132s
sys 0m0.281s
资源消耗
chaosblade-operator 1.6.1 版本
这次安装 chaosblade-operator 1.6.1 版本
helm install chaosblade-operator chaosblade-operator-1.5.0.tgz
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 20;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
注入耗时
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 5m
{"code":200,"success":true,"result":"fe8ebc493bda3d7e"}
real 0m5.537s
user 0m0.525s
sys 0m0.067s
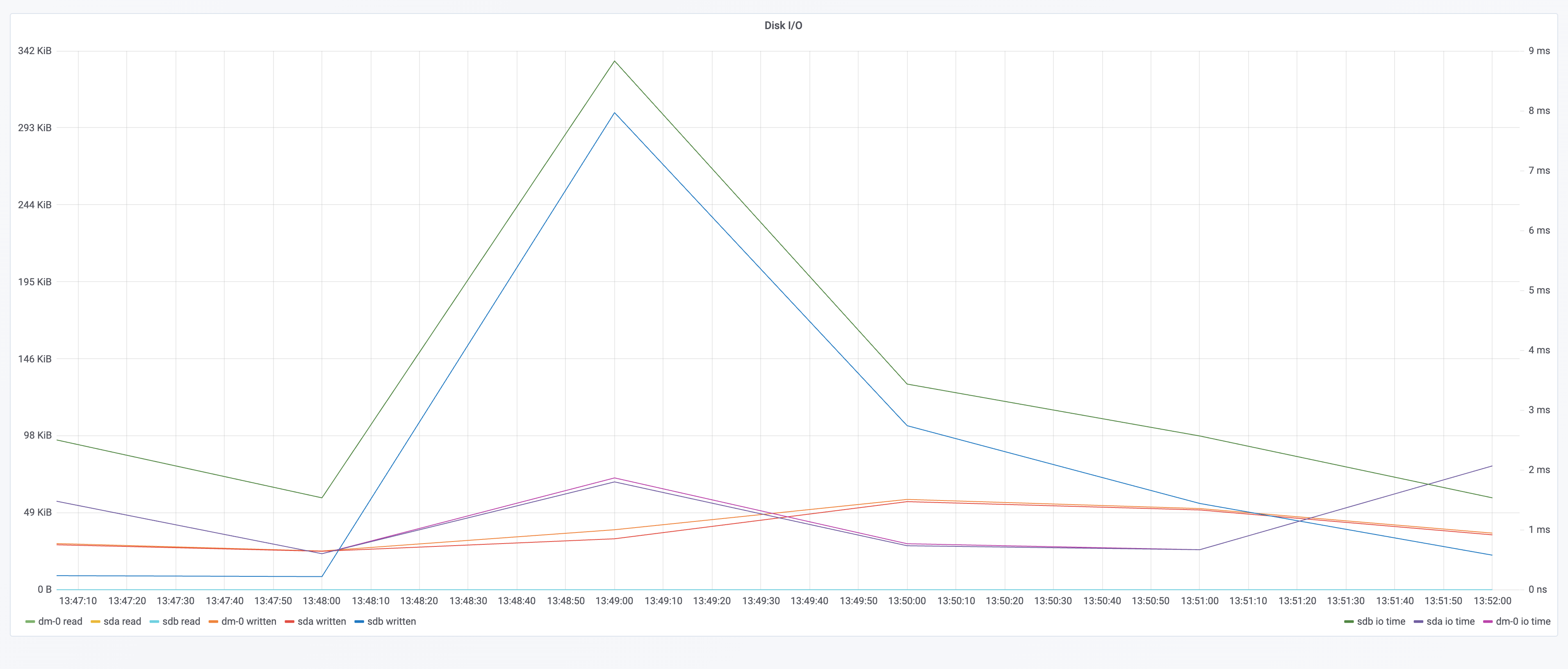
资源消耗
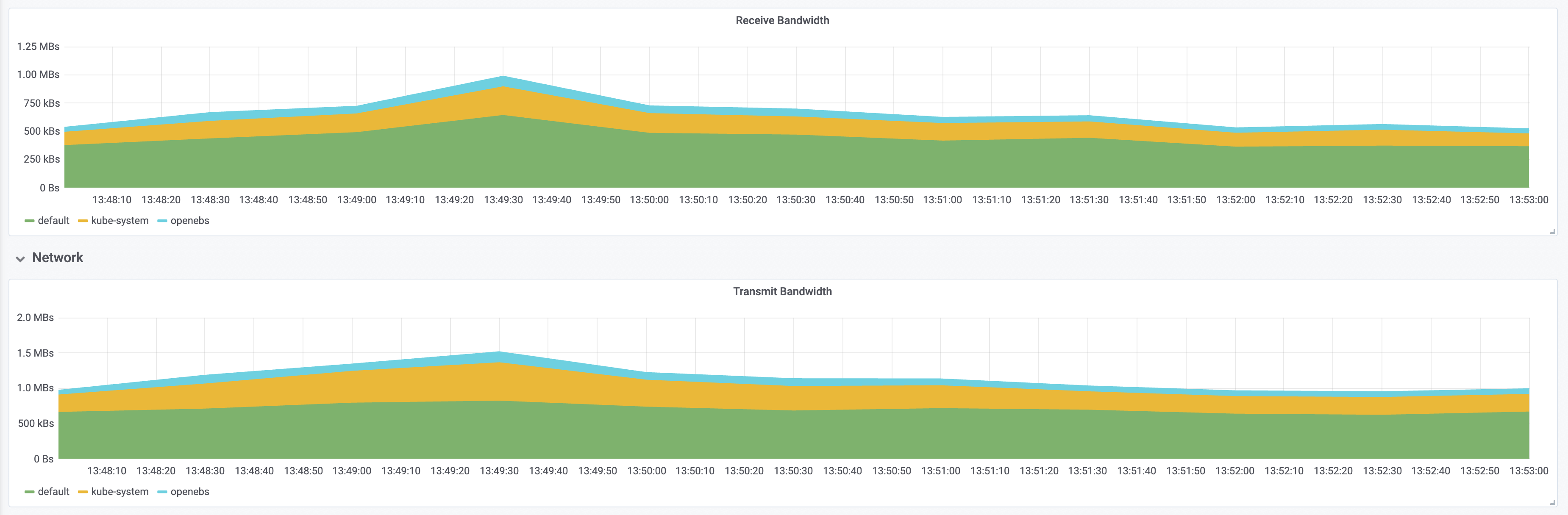 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 50;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 50;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
注入耗时
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 5m
{"code":200,"success":true,"result":"a4d9c4c9c16642b5"}
real 0m24.519s
user 0m0.597s
sys 0m0.071s
资源消耗
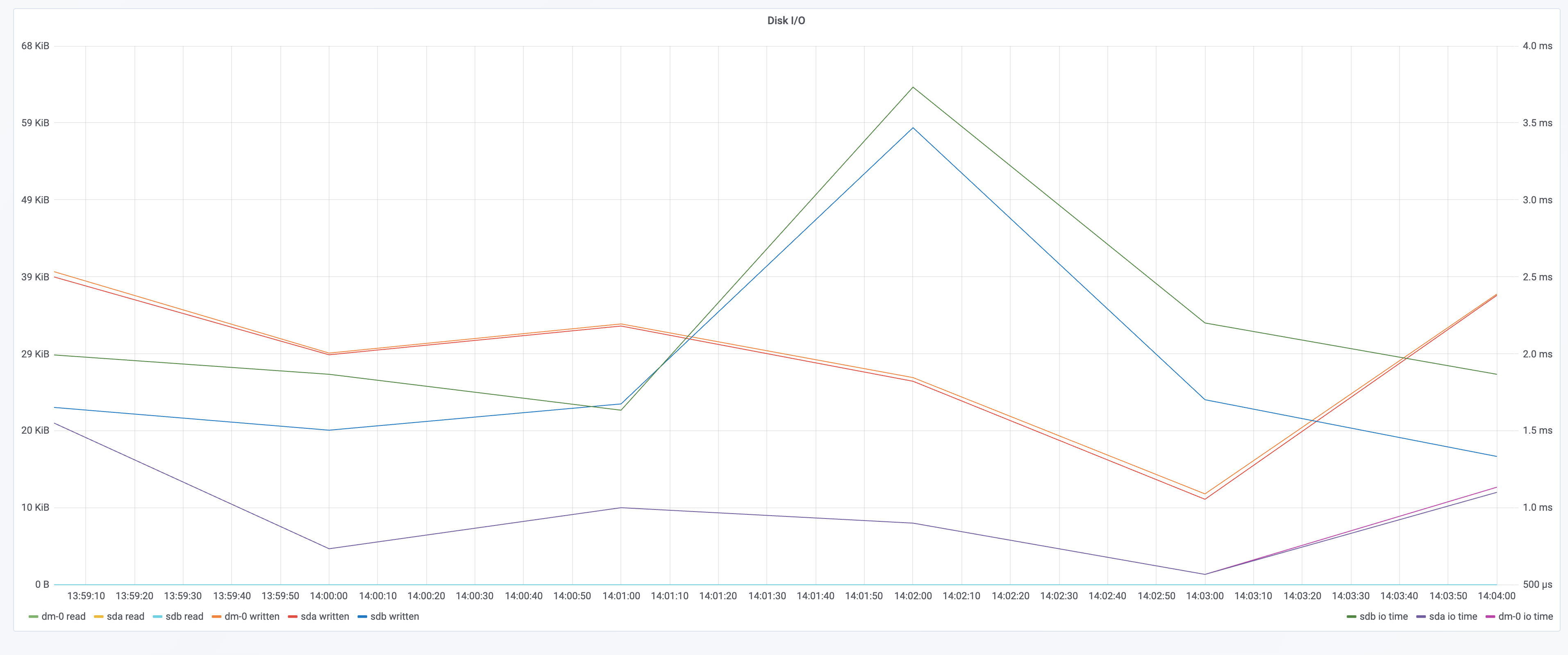
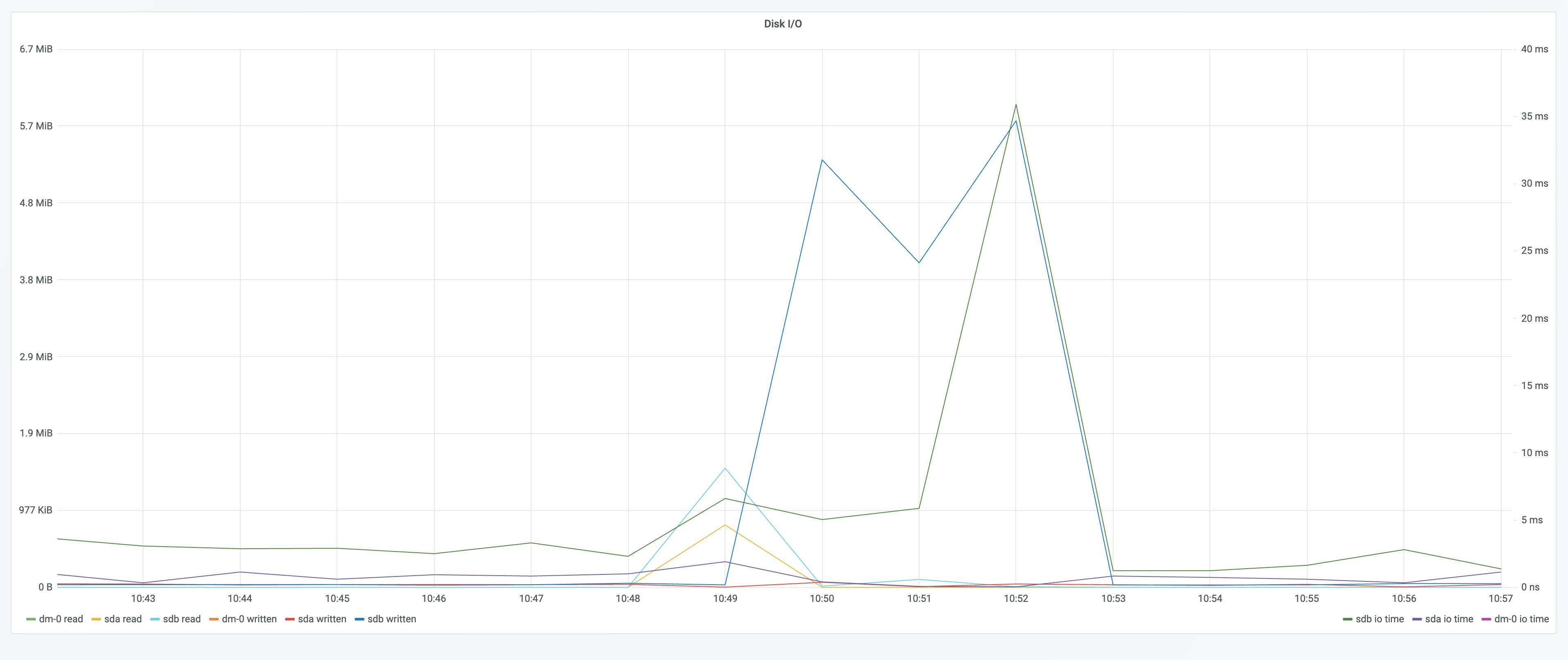
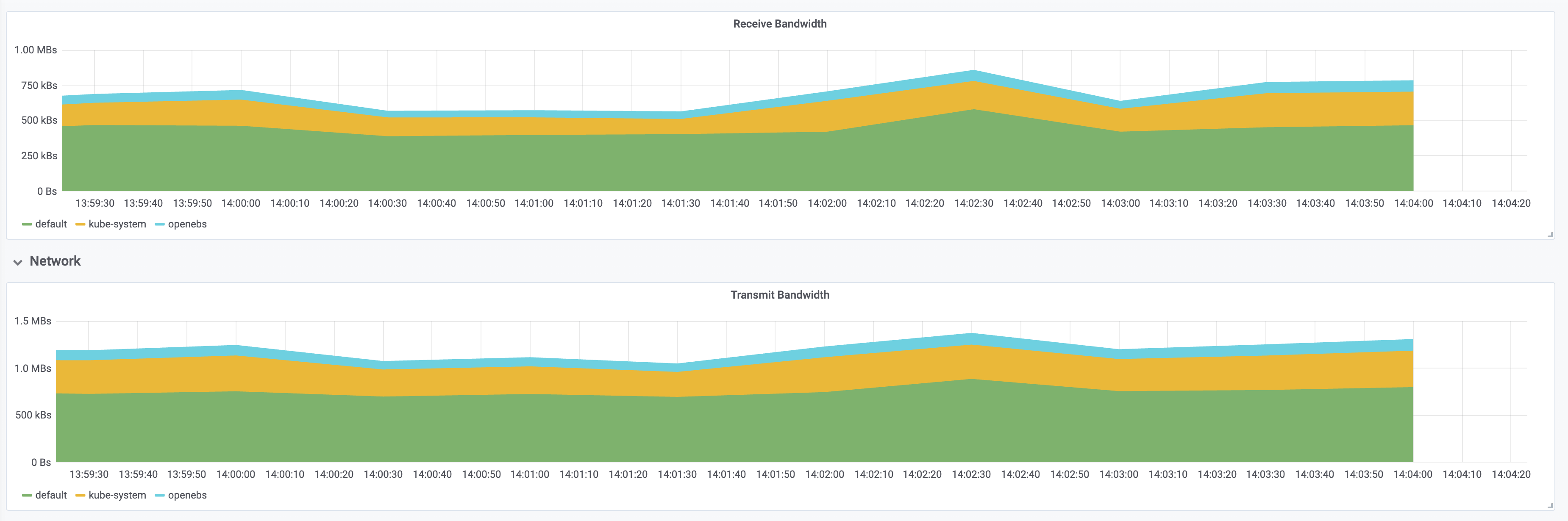 在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 100;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
在 kubernetes 中部署 tomcat deployment 资源类型,副本数设置为 100;通过 chaosblade cli 注入 CPU load 场景,指定 CPU 使用率为 60,通过标签来筛选出所有 pod,设置等待时间为 5 分钟;
注入耗时
time ./blade create k8s pod-cpu load --kubeconfig ~/.kube/config --namespace default --cpu-percent 60 --labels app=tomcat --waiting-time 5m
{"code":200,"success":true,"result":"f4f4790a369cc448"}
real 1m46.554s
user 0m0.696s
sys 0m0.055s
资源消耗
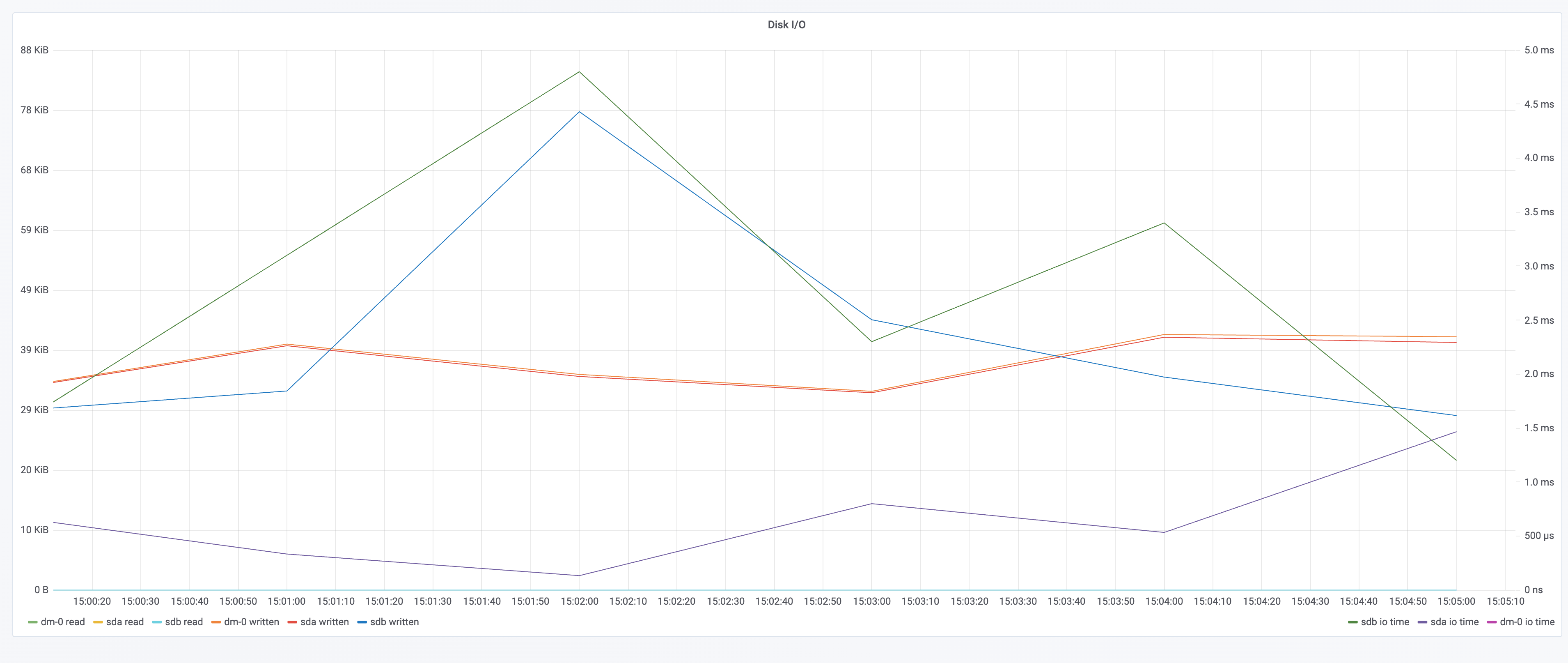
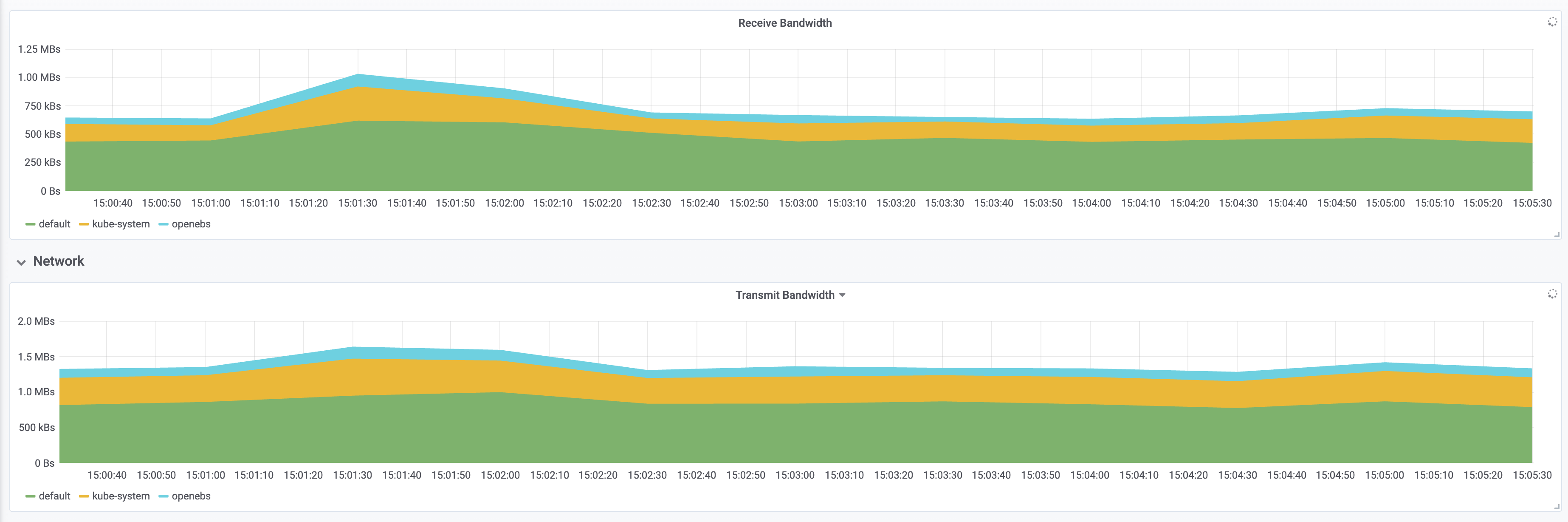
实验总结
chaosblade-operator 1.5.0 版本
| pod 数量/影响范围 | 注入耗时 | 磁盘IO影响 | 网络带宽影响 |
|---|---|---|---|
| 20 | 57s | 略微影响 | 影响大 |
| 50 | 2m25s | 影响大 | 影响大 |
| 100 | 4m59s | 影响极大 | 影响极大 |
chaosblade-operator 1.6.1 版本
| pod 数量/影响范围 | 注入耗时 | 磁盘IO影响 | 网络带宽影响 |
|---|---|---|---|
| 20 | 5s | 几乎无影响 | 几乎无影响 |
| 50 | 27s | 几乎无影响 | 几乎无影响 |
| 100 | 1m46s | 几乎无影响 | 几乎无影响 |
通过实验结果对比和观测图可以很明显的看到,chaosblade-operator 1.6.1 版本在注入过程中对在资源消耗方面几乎没有任何影响,注入耗时也有明显的提升; 对于其他新特性,比如兼容性提升、只读文件系统pod支持、无侵入等,也可以主动尝试去做更多的实验,相信你会有更深的理解。
思考
Java 场景支撑
ChaosBlade 对于容器 Java 场景的实现,是通过 JVM attach javaagent 的能力实现的,也就意味着 JVM 在 attach 的时候必须能够查找到 javaagent.jar 包所在路径,所以目前必须将 javaagent.jar 复制进容器;如何能够更优雅做到容器 Java 场景的注入仍然值得我们去探索和突破。
Node 级别演练支撑
ChaosBlade Operator 对于 Kubernetes Node 级别的演练支持是有限的,在 Node 场景注入故障时候,真正注入的是 chaosblade-tool 容器,chaosblade-tool 默认也只是进程和网络命令空间处在宿主机级别,因此在 chaosblade-tool 容器中支持网络延时、网络丢包、杀进程等场景,其实也是等同 Node 维度的网络延时、网络丢包、杀进程等场景; 对于其他 Kubernetes Node 的支持、并不能真正做到 Node 维度,比如 CPU、内存、磁盘IO 等必须得在 chaosblade-tool 容器没有被限制资源的情景下,才勉强算 Node 维度;而文件系统、Java 场景等目前是没有办法做到的;从另外一个角度出发思考,我们是否需要这些场景,在通常情况下在主机(Node)上安装 chaosblade 完全能够支持全部场景了。
相关链接 ChaosBlade 官方网址: https://chaosblade.io/ ChaosBlade Github: https://github.com/chaosblade-io/chaosblade ChaosBlade 钉钉社区交流群:23177705
作者简介:
叶飞(Github账号:tiny-x)ChaosBlade Maintainer。目前主要关注于混沌工程、云原生以及 Linux 内核相关。