
ChaosBlade is Alibaba's open-source chaos engineering project created in 2019. It has been added to CNCF Sandbox. At first, ChaosBlade was a multi-environment and multi-language chaos engineering experimental tool but developed into a multi-cluster, multi-environment, and multi-language chaos engineering platform called chaosblade-box. The platform supports experimental tool hosting and automatic tool deployment. The user's energy is focused on solving high-availability problems in the cloud-native process through chaos engineering and a unified user experiment interface. This article introduces ChaosBlade in detail from three stages, including the abstraction of the chaos experimental model, the open-source process of the chaos experimental tool, and the update of the chaos engineering platform.
In this year's trusted cloud evaluation, the Alibaba Cloud fault drill platform passed the highest level (advanced certification required by the trusted cloud chaos engineering platform) with the highest score.
Chaos Experimental Model
The ChaosBlade project covers chaos experimental scenarios, such as basic resources, application services, and container services. In the beginning, the design of the experimental tool considers the unification of scenarios and the model, which facilitates the expansion and accumulation of scenarios and provides a model basis for the platform-hosted experimental tool to realize the unified scenario call. All experimental scenarios in the ChaosBlade project follow this experimental model design, which is described in detail below through the derivation, introduction, significance, and specific application of the experimental model.
1. Derivation of the Experimental Model
Chaos experiments mainly include fault simulation. We generally describe faults in the following ways:
Disk A mounted on the machine 10.0.0.1 is full, and the service is unavailable. The slow execution of B Dubbo services on all nodes delays the call of upstream A Dubbo services, resulting in slow user access. All CPU cores on node B in Kubernetes cluster A are fully utilized, resulting in abnormal pod scheduling in cluster A. The network of pod D in the Kubernetes cluster C is abnormal, which causes access exceptions in the service related to D. We can use the following sentence to describe the failure: A certain component on a certain machine (or resources in the cluster, such as node and pod) failed, which caused the related impact. We can also view the fault detail by splitting the description, as shown in the following figure:
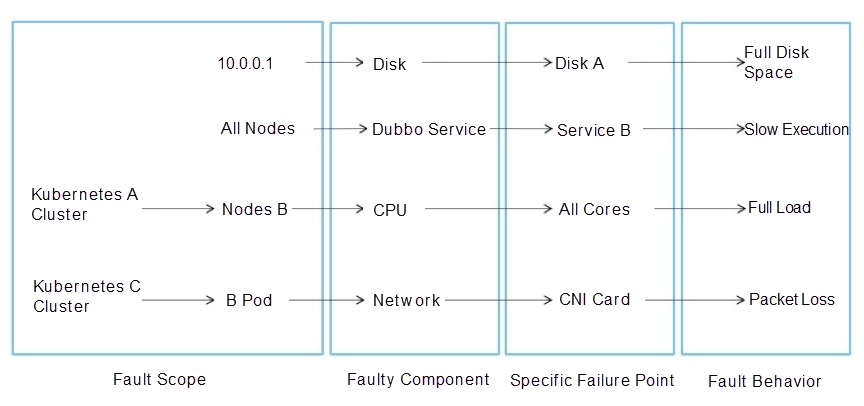
These four parts can be used to describe the existing fault scenario. Therefore, we have abstracted a fault scenario model, also known as the chaos experimental model.
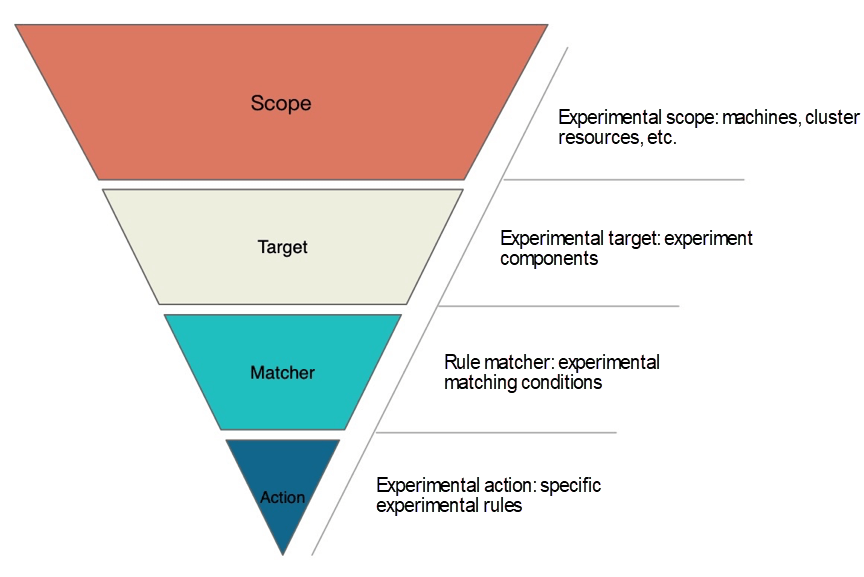
2. An Introduction to the Experimental Model
This experimental model is described in detail below:
-Scope: The scope of the experiment refers to the machines, clusters, and resources involved in the experiment. Target: The experimental target refers to the component that bears the experiment. This includes CPU, network, and disk in basic resource scenarios, application components in Java scenarios, such as Dubbo, Redis, RocketMQ, and JVM, and Node, Pod, and the Container itself in container scenarios. -Matcher: The experiment rule matcher defines relevant experiment matching rules based on the configured Target. You can configure multiple matchers. Each Target may have its own special matching conditions. For example, Dubbo and gRPC in the RPC field can be matched according to the services provided by the service provider and the services called by the service consumer. Redis in the cache field can be matched according to set and get operations. You can also extend the matcher, such as extending the experiment scenario execution strategy and controlling the experiment trigger time. -Action: These are the specific scenarios of an experimental simulation. If the Target is different, the implementation scenarios are also different. For example, disks can simulate scenarios, such as full disk, high disk I/O, or disk hardware failure. Applications can abstract experimental scenarios, such as latency, exceptions, return of specified values (such as error codes and large objects), parameter tampering, and repeated calls. For container services, we can simulate Node, Pod, Container resource exceptions, or basic resource exceptions. This model can answer the following questions that need to be clarified in implementing chaos experiments:
- What is the implementation scope of the chaos experiment?
- What is the object of implementing the chaos experiment?
- What are the conditions under which the subject triggers the experiment?
- What experimental scenarios are implemented?
3. The Significance of the Experimental Model
The model has the following features:
- Concise: It has clear levels and is easy to understand.
- General-Purpose: It covers all current fault scenarios, including basic resources, application services, container services, and cloud resources.
- Easy to Implement: It is convenient to define clear interface specifications, and the expansion of experimental scenarios is simple to implement.
- Language- and Field-Independent: It can be implemented in multiple languages and applied to multiple fields.
This model has the following meanings:
- More accurate description of chaos experimental scenarios
- A better understanding of chaos experiment injection
- Convenient accumulation of existing experimental scenarios
- Discovery of more scenarios based on the model
- More standardized and concise chaos experimental tools
4. Application of the Experimental Model
The application of the chaos experimental model is summarized below:
- The chaos experimental model parameterizes the experimental scenario variables and normalizes the parameters.
- The model can achieve the horizontal expansion of the experimental scenarios in other fields.
- The chaos experimental model can be combined with standardization in other fields to facilitate the vertical expansion of scenarios.
- Upper-layer scenarios in a field can reuse the scenario that follows the definition of the chaos experimental model.
- The scenario description declared by the chaos experimental model can be well-connected to ChaosBlade.
- Following the experimental model, the upper chaos experimental platform can be constructed easily.
The following section focuses on ChaosBlade, a chaos engineering tool implemented based on this model.
Chaos Engineering Experiment Tool: ChaosBlade
In the beginning, Alibaba introduced chaos engineering to solve the dependency problem of microservices. Later, chaos engineering was used to verify the steady state of business services and cloud services. Then, it was used to guarantee the business continuity of public cloud and private cloud and verify the stability of cloud-native systems. Alibaba has accumulated rich scenarios and practical experience. At that time, the open-source tools related to chaos engineering had problems, such as scattered scenario capabilities, difficulty getting started, lack of experimental model standards, and difficulty expanding and accumulating scenarios. These problems make it difficult to realize platformization, and it is difficult to include these tools on one platform. Therefore, the execution tool ChaosBlade of chaos engineering experiment was opened. The section below describes it in detail through scenarios, usage methods, architecture design, and examples.
1. Chaos Experimental Scenario
At the beginning of designing ChaosBlade, the ease of use and the convenience of scenario expansion are considered, which helps everyone use the tool and expand more experimental scenarios according to their needs. Following the chaos experimental model, a unified and concise execution tool was provided. The chaos experimental tool supports system platforms, such as Linux, Windows, Docker, and Kubernetes. It covers applications in Java, Golang, JavaScript, and C++. It involves more than 200 experimental scenarios and more than 3,000 experimental parameters (v1.0.0-GA). The following scenarios are included:
- Basic Resources: CPU, memory, network, disk, process, kernel, etc.
- Application Services: Databases, caches, messages, JVM, microservices, etc. Any kind of method can be specified to inject various complex experimental scenarios, and any method or a line of code can be specified to inject delay, variable, return value tampering, and other experimental scenarios.
- Docker Containers: Experimental scenarios, such as killing containers and CPU, memory, network, disk, and process in containers
- Kubernetes Platform: Experimental scenarios, such as CPU, memory, network, disk, and process on nodes, experimental scenarios in Pod network and the Pod itself, such as killing Pod, and experimental scenarios in containers, such as the preceding Docker container
- Cloud Resources: Alibaba Cloud ECS downtime and other experimental scenarios
2. Tool Usage

ChaosBlade is a tool that can be used by downloading and decompressing directly. It does not need to be installed. The calling mode it supports includes a CLI mode that directly executes blade commands.
For example, in the figure above about network latency, if you add the -h parameter, you can see a very perfect command prompt. For instance, if I want to call port 9520 to experiment on network packet loss and align the previous experimental model, its target is network, its action is packet loss, and its matcher is to call the remote service port 9520. After successful execution, the experimental results will be returned. Each experimental scenario is regarded as an object, and it will return the UID. This UID is used for subsequent experimental management, such as destroying and querying experiments. To destroy the experiment, that is, to restore the experiment, execute the blade destroy command.
Another way to call ChaosBlade is Web mode, which exposes HTTP services by executing server commands. At the upper level, if you build your chaos experimental platform, you can call ChaosBlade directly through HTTP requests.
3. Tool Architecture Design
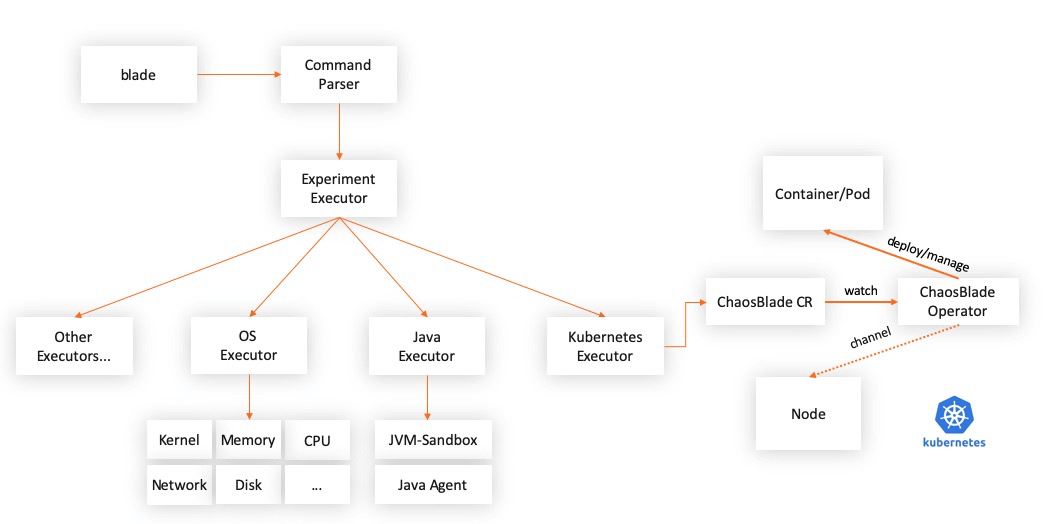
ChaosBlade is packaged into independent projects according to the field, and each project is implemented according to the best practices of each field. This meets the usage habits of each field and establishes the relationship with the chaosblade cli project through the chaos experimental model, making it convenient to use ChaosBlade for uniform calls. The experimental scenarios in each field are described in YAML files based on the chaos experimental model and exposed to the upper chaos experiment platform. The platform automatically senses the changes of the experimental scenario according to the changes in the description files. The platform can also be developed when no new scenarios are needed. This way, the chaos platform can focus more on other parts of the chaos project. The currently included actuator items are listed below:
- chaosblade is a chaos experiment management tool. It includes commands for creating experiments, destroying experiments, querying experiments, preparing experiment environments, and revoking experiment environments. It is an execution tool for chaos experiments. The execution methods include CLI and HTTP. It provides complete descriptions of commands, experimental scenarios, and scenario parameters. The operations are concise and clear.
- chaosblade-spec-go is the Golang definition of the chaos experimental model, which helps implement scenarios that use the Golang language.
- chaosblade-exec-os implements basic resource experimental scenarios, such as CPU, network, memory, and disk.
- chaosblade-exec-docker implements Docker container experimental scenarios, standardized by calling the Docker API.
- chaosblade-operator implements experimental scenarios on Kubernetes platforms. Chaos experiments are defined by the Kubernetes standard CRD mode. It is very convenient to use Kubernetes resource operations to create, update, and delete experimental scenarios, including using methods, such as kubectl and client-go. It can also be executed using the preceding chaosblade cli.
- chaosblade-exec-jvm implements Java application experimental scenarios. It is dynamically mounted using Java Agent technology without any access. It can be used at no cost, supports uninstallation, and can completely recycle every resource created by the Agent.
- chaosblade-exec-cplus implements C++ application experimental scenarios. It uses GDB technology to implement method-level and code line-level experimental scenario injection.
4. Examples
An example of Dubbo microservice is used to introduce the use of ChaosBlade. This microservice Demo involves three-level calls. The consumer calls the provider, and the provider calls the base. The provider also calls the mk-demo database. The provider and the base have two instances.
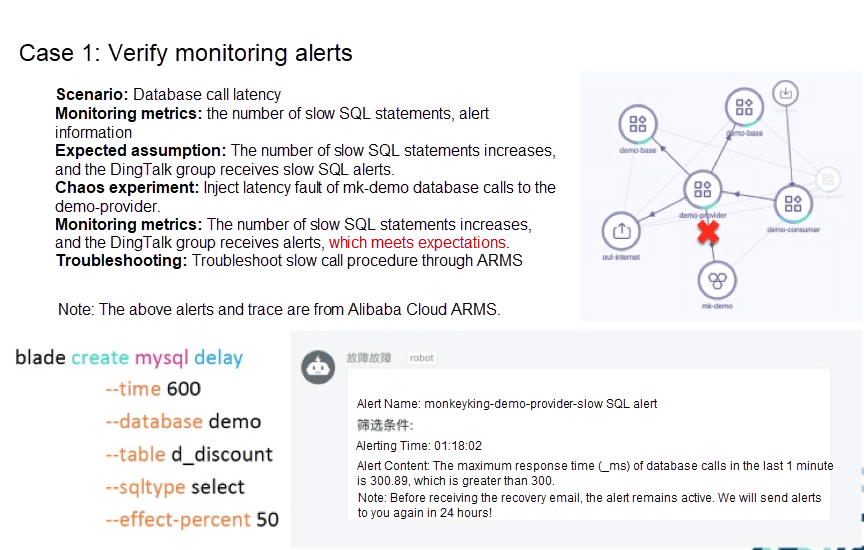
The experimental scenario of this example is database call delay. First, we define the monitoring metrics: the number of slow SQL statements and alert information. The expected assumption: the number of slow SQL statements increases, and the DingTalk group receives slow SQL alerts. Next, perform the experiment. We use chaosblade directly. You can look at the lower left part of the figure above. When we inject the calls of MySQL query for demo-provider, if the database is demo and the table name is d_discount, 50% of query operations will be delayed by 600 milliseconds.

We use Alibaba Cloud ARMS for monitoring and alerting. As you can see, the DingTalk group receives an alert soon after performing the chaos experiment. The effect meets the expectation by comparing it with the monitoring metrics defined earlier. However, it should be noted that the results from this instance does not mean it will meet the expectation in the future, so continuous verification by chaos engineering is needed. If slow SQL statements occur, ARMS tracing analysis can be used to troubleshoot and locate them. You can see which statement is slow in execution.
Chaos Engineering Platform: chaosblade-box
Users expect to focus on solving system high availability problems through chaos engineering rather than the selection and deployment of experimental tools. Thus, ChaosBlade is upgraded, and the open-source chaosblade-box, a chaos engineering platform, is provided. The platform hosts mainstream chaos experimental tools, automates the deployment of tools, and implements chaos engineering through a unified operation page.
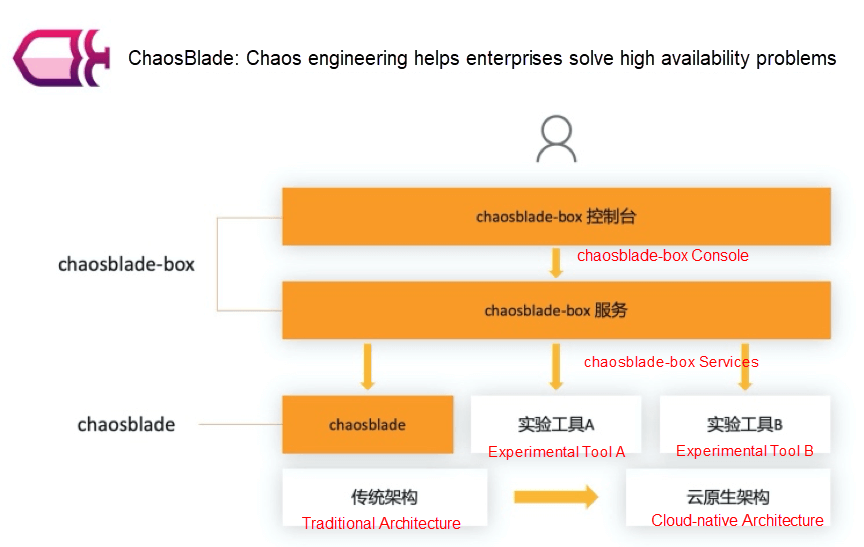
The following section describes chaosblade-box through its features, architecture design, and use cases.
1. Features
It has the following features:
- Support for Open-Source Experimental Tool Hosting: The platform can host mainstream experimental tools in the industry, such as its own chaosblade and external LitmusChaos. The chaos mesh experiment tool will also be hosted in the future.
- A Wide Range of Experimental Scenarios: Basic resources (such as CPU, memory, network, disk, process, kernel, and file), application services in multiple languages (such as Java, C++, JavaScript, and Golang), and Kubernetes platform (covering resources such as Container, Pod, and Node)
- Automated Deployment of Experimental Tools: Manual deployment of experimental tools is unnecessary. It can realize automatic deployment of experimental tools on hosts or clusters.
- Unified User Interface of Chaos Experiments: Users do not need to care about the use of different tools, and they can perform chaos experiments on the unified user interface.
- Multi-Dimensional Experiment Mode: It supports experiment orchestration from the dimension of hosts to Kubernetes resources and applications.
- Integrated Cloud-Native Ecosystem: It uses Helm for deployment management, integrates Prometheus for monitoring, and supports the hosting of cloud-native experimental tools.
2. Platform Architecture Design
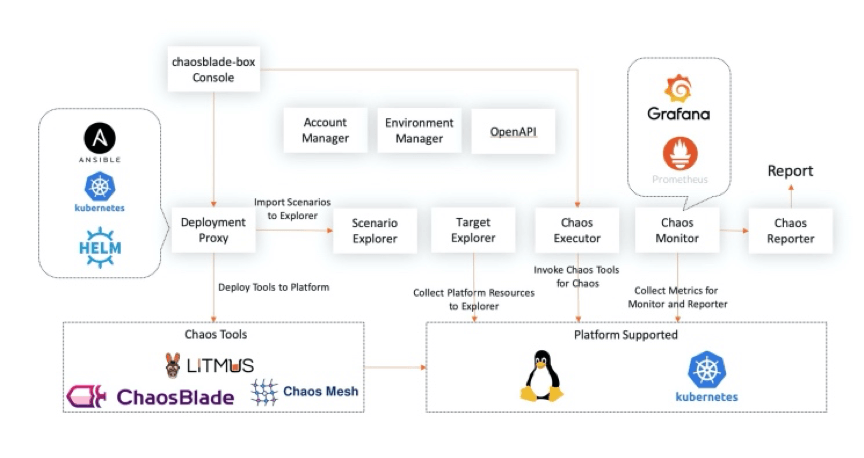
You can use the console page to automate the deployment of managed tools, such as chaosblade and LitmusChaos, and unify the experimental scenarios according to the chaos experimental model established by the community. You can also divide the target resources according to hosts, Kubernetes, and applications and use the target manager to control them. On the experiment creation page, you can select target resources in a visible way. The platform executes experimental scenarios of different tools by calling chaos executor. You can observe the experiment metrics with access to Prometheus monitoring. Rich experiment reports will be provided in the future. The deployment of chaosblade-box is also very simple.
You can see the details on here.
3. Instructions
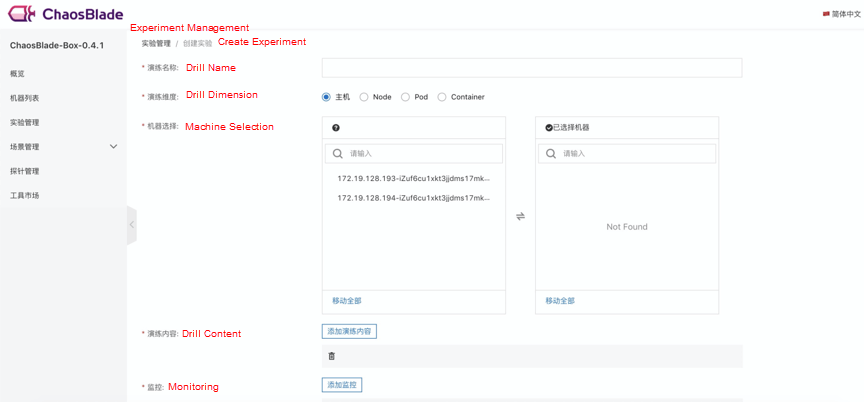
After the installation and deployment are completed, you can configure the Kubernetes cluster or host information to view the cluster or host data on the Machine List page. Click Experiment Management to create the experiment. The drill dimensions include the host, node, pod, and container. After you select the corresponding dimension, the corresponding resource list appears, and you can select it easily. The drill contains all hosted experimental scenarios. After the experiment is created, you are redirected to the drill details page automatically. Click Execute to jump to the task details page.
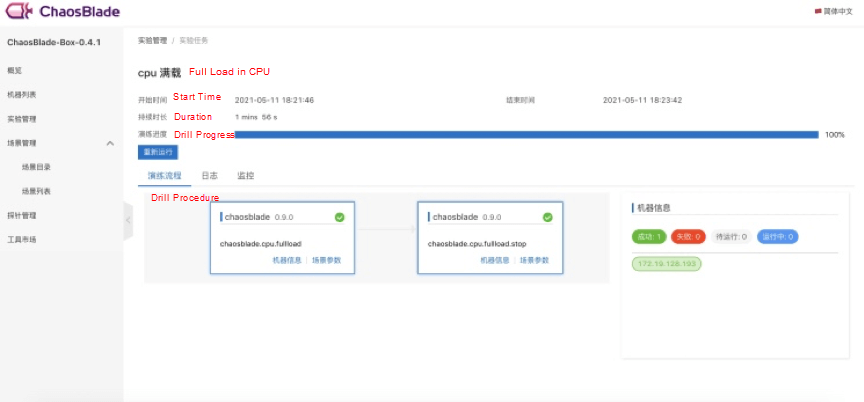
The page of drill task details displays the basic information of the experiment and the status of the experiment task. You can easily control the experiment and clarify the status of the experiment task.
The Future Planning
1. ChaosBlade
Based on cloud-native, ChaosBlade will provide a chaos engineering platform and chaos engineering experimental tools for multiple clusters, multiple environments, and multiple languages. Experimental tools continue to focus on the richness and stability of experimental scenarios, support more Kubernetes resource scenarios, normalize the experimental scenario standards of application service, and provide a standard implementation for experimental scenarios in multiple languages.
2. chaosblade-box
In the future, the core functions of the Alibaba Cloud fault drill platform (with Advanced Certification of Chaos Engineering Platform in Trusted Cloud) will be open-sourced and integrated with the existing chaos engineering platform to open more capabilities. At the same time, it simplifies the deployment and implementation of chaos engineering tools. In the future, it will host more chaos experimental tools and be compatible with mainstream platforms. This way, it can implement scenario recommendations, provide integrated business and system monitoring, output experimental reports, and complete closed-loop chaos engineering operations on an easy-to-use basis.
About Authors
Xiao Changjun (Qionggu) is an Alibaba Technical Expert, Founder and Maintainer of the open-source project ChaosBlade, Head of Alibaba Cloud fault drill platform, an expert of Trusted Cloud Standards, and a chaos engineering expert with years of experience in distributed system architecture and stability construction.
Sang Jie works in the R&D Center of Agricultural Bank of China and is engaged in big data R&D in financial-related systems.